Kurzfassung
TransferEngine ist eine portable RDMA‑Abstraktion, die in Projekten wie pplx garden eingesetzt wird, um KV‑Cache‑Streaming, MoE‑Dispatch und punktuelle Weight‑Transfers für Trillion‑Parameter‑Modelle zu ermöglichen. Dieser Text erklärt, wie die Technik in vorhandenen GPU‑Clustern funktioniert, welche Voraussetzungen sie stellt und welche praktischen Schritte nötig sind, um ein Proof‑of‑Concept umzusetzen — mit Hinweisen zu Risiken und Messgrößen.
Einleitung
Die Idee, Trillion‑Parameter‑Modelle auf bestehenden GPU‑Clustern auszuführen, klingt wie eine Aufgabe für spezialisierte Rechenzentren. TransferEngine bringt die RDMA‑Mechanik auf eine einheitliche Ebene und erlaubt, dass KV‑Caches, MoE‑Dispatches und punktuelle Gewichtstransfers über vorhandene Netzwerkkarten laufen. In diesem Beitrag beschreibe ich praxisnah, welche Teile der Technologie maßgeblich sind, welche Risiken zu beachten sind und wie ein kleines Team in wenigen Schritten testen kann, ob die Lösung in der eigenen Infrastruktur funktioniert.
Warum TransferEngine für Trillion‑Parameter‑Modelle
Die zentrale Motivation hinter TransferEngine ist pragmatisch: große Modelle brauchen Verbindungen, die hohe Bandbreite und niedrige Latenz konsistent liefern — ohne dabei auf proprietäre Stacks zu setzen. TransferEngine fasst RDMA‑Funktionen zusammen und bietet Entwicklern eine vergleichbare Schnittstelle für unterschiedliche NIC‑Typen. Das ist besonders wichtig, wenn bereits vorhandene Cluster weitergenutzt werden sollen und kein kompletter Hardware‑Umstieg geplant ist.
Für Anwender bedeutet das: Statt ein Modell strikt auf monolithische GPU‑Farmen zu beschränken, erlaubt die Kombination aus TransferEngine und Komponenten aus pplx garden, verschiedene Knoten für Prefill, Decode oder Speichern von KV‑Caches zu verknüpfen. Praktisch heißt das, dass der KV‑Cache nicht notwendigerweise lokal in jeder GPU liegen muss; er kann segmentiert und bei Bedarf gestreamt werden. Dieses Muster öffnet Wege, die Rechenlast flexibler zu verteilen und Hardwareeffizienz zu verbessern, ohne das gesamte System neu zu denken.
„TransferEngine bietet eine sinnvolle Brücke zwischen vorhandener Netzwerkinfrastruktur und den Anforderungen sehr großer Sprachmodelle.“
Wichtig zu betonen: viele Performance‑Angaben stammen aus den Veröffentlichungen und dem Code der ursprünglichen Entwickler. Aussagen zu Peak‑Durchsatz oder End‑to‑End‑Latzenzen sind vielversprechend, sollten aber in der Zielumgebung verifiziert werden. Die Technologie ändert damit nicht allein das Modell, sie ändert die Annahmen, die man an Infrastruktur stellt — und das kann für Teams, die nicht komplett neue Hardware anschaffen wollen, einen echten Vorteil darstellen.
In der praktischen Umsetzung bleibt die Frage, wie stark sich das Verhalten von Netzwerk, Treibern und GPUs auf reale Latenzen auswirkt. Deshalb ist der Übergang zur Implementierung immer eine Messung, nicht nur eine Konfiguration.
Tabellen helfen, Merkmale knapp zu vergleichen:
| Merkmal | Wann relevant | Auswirkung |
|---|---|---|
| RDMA‑Abstraktion | Heterogene NICs | Weniger Portierungskosten |
| KV‑Cache‑Streaming | Disaggregierte Inferenz | Speicherflexibilität |
Technische Architektur: RDMA‑Abstraktion und KV‑Cache‑Streaming
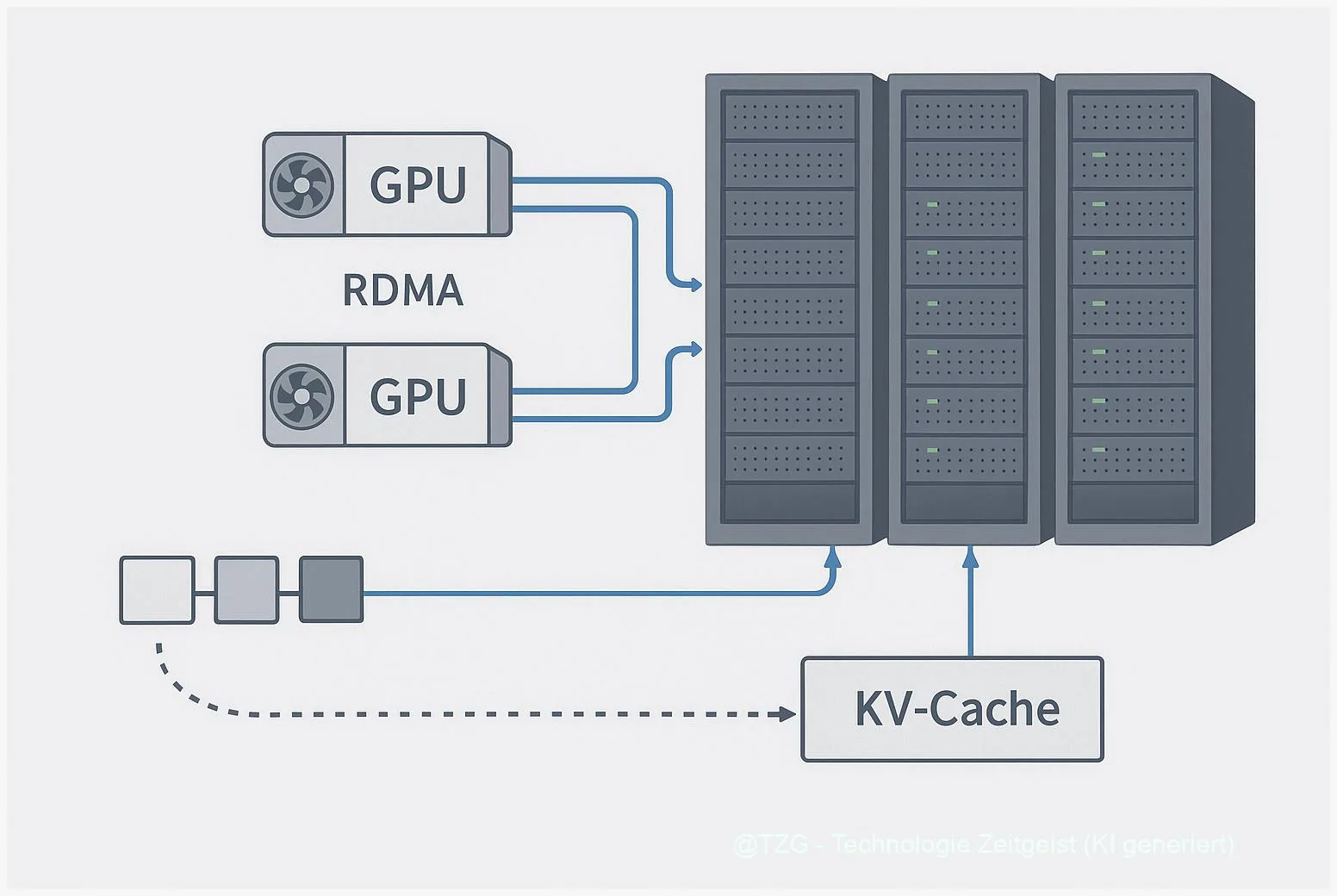
TransferEngine kapselt die Low‑Level‑Unterschiede von libibverbs, libfabric und Cloud‑APIs, sodass Entwickler auf eine vergleichbare API zugreifen. Im Kern geht es um ein konsistentes Verhalten für Schreib‑ und Leseoperationen, Completion‑Signalisierung und um effiziente Kopierpfade wie GPUDirect/GDRCopy. Aus Architektursicht ist das ein pragmatischer Mittelweg: Man akzeptiert, dass die Hardware variiert, bietet jedoch stabile Semantiken für die Kommunikationsmuster, die LLMs benötigen.
Ein zentrales Muster ist das KV‑Cache‑Streaming: anstelle großer, komplett lokaler Speicherbilder werden Cache‑Segmente on‑demand zwischen Prefill‑ und Decode‑Worker verschoben. Das kann über gepagte Writes, Scatter/Gather‑Pipes und ein UVM‑basiertes Watching erfolgen. Die Implementierungen zeigen, wie man über NIC‑Aggregation und durchdachte Schreibmuster den Durchsatz optimiert, ohne jede Node gleich auszustatten.
Für MoE‑Modelle ist ein weiterer Hebel wichtig: Dispatch/Combine‑Algorithmen schichten Routing und Zusammenführung so, dass einzelne Expert‑Updates punktuell über RDMA ausgetauscht werden. In der Praxis ist das anspruchsvoll, weil es Koordination zwischen Host‑Proxy, GPU‑Memory und NIC erfordert. pplx garden liefert hier Kernel‑Bausteine, die bewährte Muster umsetzen — das spart Entwicklungszeit, verpflichtet aber zugleich zur Kontrolle über Treiber und Rechte.
Wesentliche technische Voraussetzungen sind aktuelle Linux‑Kernel‑Features, CUDA‑Versionen und Bibliotheken wie libfabric. Ohne diese Basispakete läuft das System nicht stabil. Ebenso wichtig ist ein robustes Fehler‑Handling: Timeouts, Retries und saubere Cancel‑Semantiken verhindern inkonsistente Caches und verloren gegangene Writes.
Schließlich ist es nützlich, das Design als Reihe von Messpunkten zu betrachten: Latenz bei 1‑Byte‑Handshakes, Durchsatz über aggregierte Links, und die p50/p95/p99‑Verteilungen bei Decode‑Pfaden. Diese Metriken erlauben, Hypothesen zu prüfen und Anpassungen zielgerichtet vorzunehmen.
Betrieb: Hardware, Voraussetzungen und Fallstricke
Beim Betrieb geht es weniger um Fiktion als um Details: Welche NICs sind vorhanden, wie viele Ports pro Server, wie sieht die PCIe‑Topologie aus und welche Kernel‑Capabilities lassen sich in Containern abbilden? TransferEngine funktioniert am besten in Umgebungen, in denen libibverbs, GPUDirect und GDRCopy verlässlich installiert sind. In vielen Clouds müssen diese Elemente geprüft werden, bevor ein produktiver Lauf sinnvoll ist.
Ein häufiger Fallstrick sind Rechte: Einige Optimierungen verlangen erhöhte Kernel‑Capabilities oder Container‑Konfigurationen, die in Multi‑Tenant‑Setups nicht gewünscht sind. Das führt zu Kompromissen: Entweder man akzeptiert eingeschränkte Performance oder richtet dedizierte Subnetze mit angepassten Policies ein. Beide Optionen haben Kostenfolgen und sollten vor einem Produktivstart abgewogen werden.
Bei AWS‑EFA‑Setups ist zusätzlich zu beachten, dass die beobachtete Bandbreite oft von NIC‑Aggregation und Topologie abhängt. Herstellerberichte nennen aggregierte Bandbreiten als erreichbare Werte; reale Messungen können je nach Kabel, Switch‑Konfiguration und CPU‑Proxy‑Overhead abweichen. Aus diesem Grund ist eine frühe Messung im Zielnetz zentral: ohne sie bleibt die Projektplanung spekulativ.
Weiterhin verlangt die Technik robuste Observability: End‑to‑end‑Traces für Prefill/Decode, Metriken zu paged writes und detaillierte Logs für Retry‑Verhalten. Nur so lassen sich Performance‑Engpässe isolieren — sei es im Netzwerk, im PCIe‑Switching oder in Host‑CPU‑Proxys. Betriebsprozesse sollten Fehlerfälle explizit testen, insbesondere Abbrüche während Prefill‑Phasen und das Verhalten bei partiellen Reconnects.
Abschließend noch ein pragmatischer Rat: Beginnen Sie mit kleinen, reproduzierbaren Tests, dokumentieren Sie konkrete Metriken und entscheiden Sie auf Basis gemessener Werte. Die Technologie kann Kosten sparen, aber nur, wenn man die Infrastruktur kennt und die richtigen Messgrößen trennt.
Praxisplan: Proof‑of‑Concept und Migration
Ein zielgerichteter Proof‑of‑Concept (PoC) ist die sauberste Methode, um zu entscheiden, ob TransferEngine mit Ihrer Infrastruktur zusammenpasst. Der Plan beginnt klein: zwei bis vier Nodes, eine NVMe‑Node für Prefill und zwei GPUs zum Decode. Installieren Sie die nötigen Bibliotheken, starten Sie einen einfachen KV‑Cache‑Prefill und messen Sie p50/p95‑Latzenzen sowie paged‑write‑Durchsatz. Diese Metriken liefern den ersten Realitätscheck.
Im Ablauf empfiehlt sich eine schrittweise Validierung: 1) Baseline‑Messung ohne RDMA, 2) Messung mit RDMA‑Pfad auf einem ConnectX‑7‑System, 3) EFA‑Messungen in einer Cloud‑Topologie. Falls Sie auf Perplexitys Messwerte stoßen — sie liefern interessante Vergleichswerte —, behandeln Sie diese als Referenz, nicht als Garantie. Unterschiede in Topologie und Treiber können die Ergebnisse stark verändern.
Wechseln Sie danach zu einem leicht erweiterten Szenario: mehrere Decode‑Worker, MoE‑Dispatch‑Simulation und punktuelle Weight‑Transfers. Dokumentieren Sie bei jedem Schritt, welche Kernel‑Versionen, CUDA‑Releases und libfabric‑Build‑Flags eingesetzt wurden. Solche Details sind oft entscheidend, wenn Performance plötzlich anders ausfällt als im Lab.
Organisatorisch lohnt es, einen kurzen Entscheidungsrahmen zu vereinbaren: Wenn der PoC stabile Verbesserungen bringt und die benötigten Rechte vertretbar sind, lässt sich eine Pilot‑Phase mit mehr Knoten starten. Andernfalls helfen die Messdaten, kosteneffizient umzusteuern — etwa durch gezielte Hardware‑Upgrades oder Isolation kritischer Pfade.
Zum Abschluss: Planen Sie genügend Zeit für Fehlerbehandlung und Regressionsmessungen ein. Quality Gates, automatisierte Benchmarks und eine kleine Bibliothek mit Reproduktionsskripten sparen später mehr Zeit, als die anfängliche Sorgfalt kostet.
Fazit
TransferEngine und die Module aus pplx garden sind keine magische Abkürzung, aber eine pragmatische Brücke für Teams, die große Modelle auf vorhandener Infrastruktur betreiben wollen. Die Lösung reduziert Portierungskosten, fordert aber präzise Messungen und gelegentliche Kompromisse bei Rechten und Topologie. Ein sauber geplanter Proof‑of‑Concept zeigt schnell, ob die Idee zur eigenen Umgebung passt.
*Diskutieren Sie Ihre Erfahrungen in den Kommentaren und teilen Sie diesen Artikel in Ihren Netzwerken, wenn Sie den Praxisplan nützlich finden.*



Schreibe einen Kommentar