Kurzfassung
Token‑level Audio Editing ermöglicht punktuelle Änderungen in Sprachaufnahmen — ohne die gesamte Datei neu aufzunehmen. Dieses Stück erklärt praktische Anwendungen und Grenzen von Step‑Audio‑EditX und beleuchtet, wie audio LLM editing heute arbeitet, welche technischen Bausteine eine Rolle spielen und welche ethischen sowie operationellen Fragen beim Einsatz auftauchen. Lesen Sie nüchtern, aber empathisch, warum Token‑Edits vielversprechend sind — und wo Vorsicht geboten ist.
Einleitung
Sprachdateien waren lange starr: schneiden, neu aufnehmen, hoffen, dass Ton und Stimmung passen. Token‑Level Editing verändert dieses Bild. Statt die ganze Welle zu bearbeiten, lassen sich einzelne Bausteine austauschen — wie Wörter, Silben oder prosodische Nuancen. Step‑Audio‑EditX ist ein Beispiel für diesen Ansatz: Es kombiniert diskrete Audio‑Token mit großen Sprachmodellen und erlaubt iteratives Verfeinern. In diesem Text schauen wir praktisch auf Werkzeuge, Anwendungen und die Dosis Vorsicht, die bei solchen Systemen nötig ist.
Was ist Token‑Level Audio Editing?
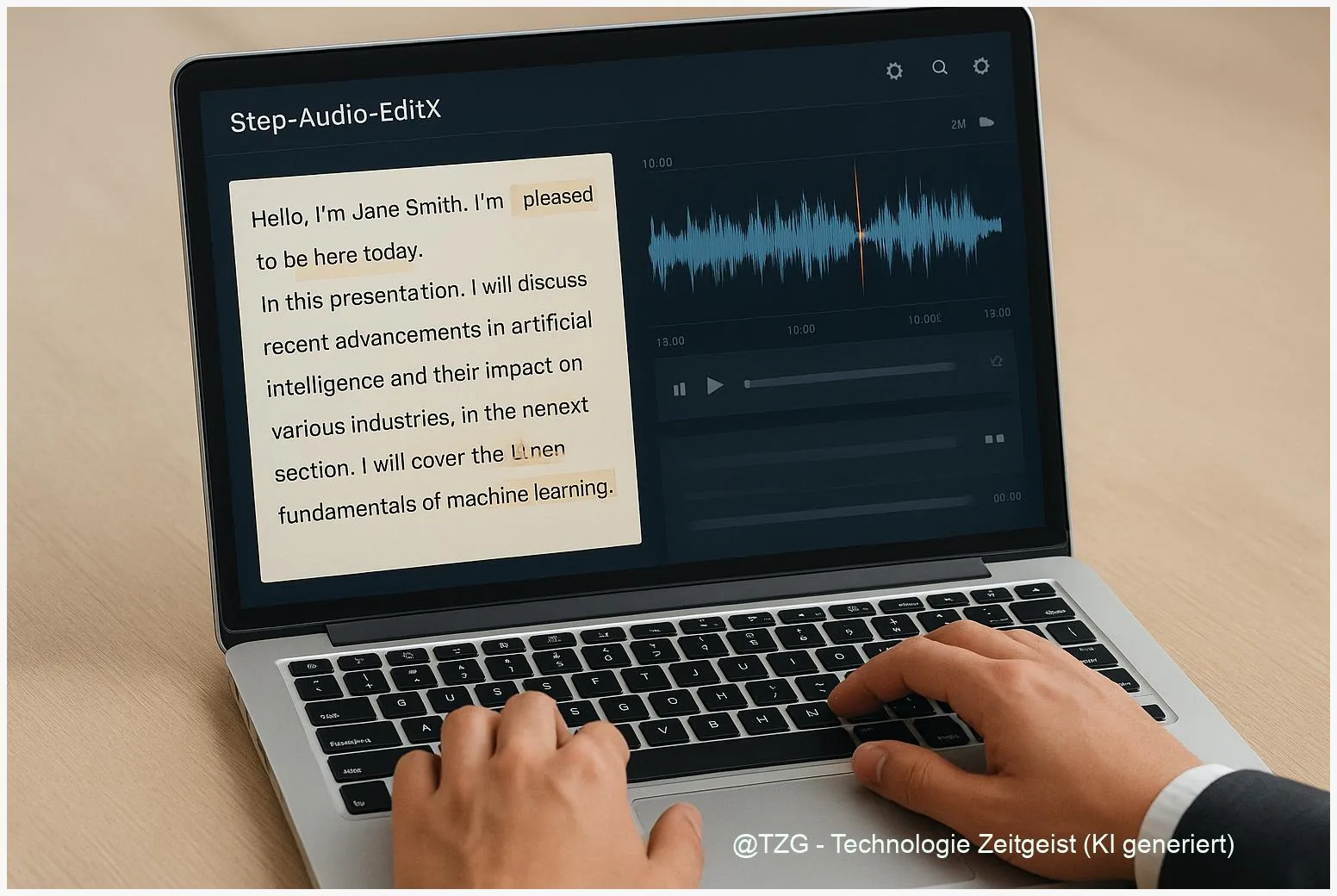
Token‑Level Audio Editing heißt: man arbeitet nicht mehr mit Rohwellen, sondern mit diskreten Repräsentationen — Tokens — die Teile der Sprachinformation kodieren. Diese Tokens können Akustik, Linguistik oder semantische Merkmale repräsentieren. Neuere Systeme nutzen zwei parallel laufende Tokenströme (ein “dual‑codebook”-Design): einer fängt linguistische, phonemische Information ein, der andere speichert Tönung, Stimmfarbe und Prosodie. Solche Trennung erlaubt feine Eingriffe: ein Wort korrigieren, einen Ausdruck emotional anpassen oder eine silbenweise Aussprache nachbessern, ohne alle Parameter zu verändern.
“Tokenbasierte Repräsentationen sind das Kleinteilige, das große Veränderungen vermeidet.” — technische Beobachtung aus aktuellen Projektberichten.
Wichtig zu wissen: Tokenizer sind nicht alle gleich. Forschung aus 2024–2025 zeigt, dass Produktquantisierung (PQ‑VAE) und duale Codebücher Index‑Probleme lösen und die Nutzbarkeit großer Codebücher verbessern. Projekte wie Step‑Audio‑EditX dokumentieren diese Architektur und nutzen sie, um präzise, iterative Edits zu ermöglichen. Das Ergebnis ist kein magischer Knopf, sondern ein flexibles Werkzeug, das Genauigkeit gegen Rechenaufwand abwägt.
Die Tabelle unten fasst zwei prinzipielle Design-Entscheidungen zusammen, die häufig auftreten:
| Merkmal | Beschreibung | Nutzen |
|---|---|---|
| Dual‑Codebook | Getrennte Tokenströme für Linguistik und Akustik | Bessere Editierbarkeit, geringeres Artefaktrisiko |
| PQ‑VAE / Produktquantisierung | Vermeidet Index‑Collapse bei großen Codebüchern | Höhere Codebook‑Nutzung, bessere Rekonstruktion |
Praktische Anwendungsfälle mit Step‑Audio‑EditX
Die versprochenen Vorteile von tokenbasiertem Editing werden am schnellsten sichtbar, wenn man konkrete Aufgaben betrachtet. Journalisten schneiden flüchtige Sätze aus Interviews sauber heraus; Produzenten korrigieren Aussprachefehler in einer Episode, ohne ganze Takes zu remastern; Übersetzerinnen passen Rhythmus und Betonung an neue Sprachen an. Step‑Audio‑EditX wird in Projektberichten als Plattform beschrieben, die genau diese Szenarien unterstützt: präzises Ersetzen von Token, iteratives Feintuning und Kontrollmechanismen für gewünschte Stimmmerkmale.
Ein typischer Workflow könnte so aussehen: 1) Aus dem Original wird ein Token‑Stream erzeugt; 2) Ein Edit‑Befehl markiert Tokenregionen (z. B. ein falsches Wort oder eine pausierte Silbe); 3) Das Modell schlägt Alternativen vor; 4) Der Produzent nimmt eine oder mehrere Iterationen an, bis Ton und Ausdruck passen. Solche Iterationen sind bewusst kurz: meist erfolgen 1–3 Feinschliffe, danach steht das Ergebnis. Diese Vorgehensweise spart Zeit und erhält die natürliche Färbung der Stimme besser als starker Post‑Processing‑Einsatz.
Weitere Einsatzfelder: Barrierefreiheit (Vorlesen mit angepasster Intonation), Gaming (charakterspezifische Sprechstile ohne erneute Aufnahmen), Sprach‑Lokalisierung für Podcasts und Dialog‑Editing in Hörspielen. Wichtig bleibt dabei die Qualitätssicherung: menschliche Ohren und ASR‑Checks ergänzen automatisierte Metriken, weil automatische Richter (LLM‑Judges) voreingenommen sein können. In Projektunterlagen wird empfohlen, menschliche Tests (MOS/MUSHRA) parallel zu automatischen Scores zu nutzen.
Kurz gesagt: Token‑level Editing eignet sich dort, wo Feinkorrekturen gefragt sind und die Originalstimme bewahrt werden soll. Für komplette Neusynchronisationen oder stark veränderte Performances bleiben klassische Studioproduktionen oft die bessere Wahl.
Technik verständlich: Tokenizer, Decoder, PPO
Hinter der Bedienoberfläche arbeiten mehrere Schichten zusammen. Zuerst wird Audio in Token zerlegt — das macht ein Tokenizer. In aktuellen Systemen gibt es oft zwei Streams: einen für sprachliche Inhalte, einen für akustische Signale. Diese Trennung erlaubt, ein Wort zu ersetzen, ohne Timbre zu zerstören. Für die Rückwandlung in hörbares Audio nutzen viele Projekte moderne Decoder‑Architekturen: Flow‑Matching für präzise Mel‑Rekonstruktion und neuraler Vocoding (z. B. BigVGAN‑ähnliche Ansätze) für natürliche Waveforms. Die genannten Komponenten sind in Veröffentlichungen zu Step‑Audio‑EditX und verwandten Arbeiten beschrieben.
Ein weiterer Technikbaustein ist Lern‑Feinabstimmung mit Präferenzsignalen: Reward‑Modelle bewerten, ob ein Edit menschlichen Präferenzen entspricht; darauf folgt ein Optimierungsverfahren wie PPO (Proximal Policy Optimization). In kürzeren Worten: das System lernt nicht nur, plausible Tokens zu produzieren, sondern solche, die Nutzerinnen bevorzugen. Projektberichte erwähnen typische Maßnahmen gegen Fehlanpassungen — etwa eine KL‑Strafe, um das Modell bei moderaten Schritten zu halten, oder adversarielle Negative, um Exploits zu verhindern.
Solche Reinforcement‑Ansätze sind mächtig, bringen aber Eigenheiten mit sich. In Technikdokumenten wird etwa von „deaf hacking“ berichtet — Situationen, in denen ein Reward‑Model Artefakte belohnt, die Menschen stören. Gegenmaßnahmen sind pragmatisch: human‑in‑the‑loop‑Checks, robuste Negative sowie Wasserzeichentechniken, die Attribution ermöglichen. Für produktive Nutzung empfehlen Expertinnen, alle automatischen Signale durch Stichproben mit echten Hörern zu validieren.
Wichtig: Obwohl viele Komponenten offen beschrieben sind, variieren Details zwischen Projekten. Wer selbst experimentiert, sollte mit kleinen Replikationsläufen beginnen und Checkpoints, Tokenizer‑Configs sowie Evaluationsskripte genau prüfen.
Risiken, Grenzen und verantwortlicher Einsatz
Technik alleine ist keine Garantie für guten Journalismus oder ethische Nutzung. Step‑Audio‑EditX und ähnliche Systeme arbeiten oft mit großen, teils proprietären Datensätzen; das schränkt Reproduzierbarkeit und Vertrauen ein, wenn Trainingsquellen nicht offen gelegt werden. Wissenschaftliche Berichte aus 2024–2025 weisen darauf hin, dass unabhängige Replikation und offene Benchmarks entscheidend sind, um claimed Leistung real zu verifizieren.
Missbrauchsrisiken sind real: täuschend echte Stimmimitate können Vertrauen untergraben und Schaden anrichten. Praktische Schutzmaßnahmen umfassen digitale Wasserzeichen, klare Nutzungsrichtlinien und Prüfpfade zur Herkunft von Trainingsdaten. Rechtliche Fragen zur Verwendung fremder Stimmen bleiben teils ungeklärt — wer immer mit solchen Tools arbeitet, muss Einwilligungen und Nutzungsrechte klären.
Operational gesehen gibt es technische Grenzen: Token‑Level Editing verlangt Rechenressourcen und spezielle Hardware; einige Projektseiten empfehlen GPUs mit ausreichend Speicher für flüssige Inferenz. Außerdem ist nicht jede Stimmkorrektur sinnvoll: starke emotionale Retuschen oder radikale Neuinterpretationen klingen oft künstlich und erzeugen Misstrauen bei Hörerinnen.
Mein Vorschlag: Wer Step‑Audio‑EditX einsetzt, sollte eine kurze Test‑Checklist nutzen: dokumentiere die Datenherkunft, führe menschliche Hörtests parallel zu automatischen Scores, nutze Wasserzeichen und halte rechtliche Freigaben schriftlich fest. So bleibt Technik hilfreich statt problematisch.
Fazit
Token‑level Editing macht Sprechen editierbar, nicht austauschbar: es ermöglicht präzise Korrekturen, bewahrt die Original‑Farbe und spart Zeit. Step‑Audio‑EditX zeigt, wie duale Tokenströme und moderne Decoder praktische Aufgaben lösen können, wenn Evaluation und Ethik gleichrangig betrachtet werden. Gleichzeitig bleibt unabhängige Replikation wichtig — viele Claims stammen aus Projektberichten und brauchen menschliche Validierung.
Wer diese Werkzeuge nutzt, sollte sie messen, dokumentieren und mit klaren Regeln betreiben. So bleibt das Ergebnis glaubwürdig und nützlich.
*Diskutiert eure Erfahrungen in den Kommentaren und teilt diesen Beitrag in den sozialen Medien!*



Schreibe einen Kommentar