Schlagwort: langchain
-

Agentische Workflows: Wie KI-Agenten mit Tools zuverlässig handeln
Agentische Workflows verbinden mehrere KI-Agenten mit externen Werkzeugen, damit komplexe Aufgaben zuverlässig erledigt werden. Das Konzept “agentische Workflows” beschreibt, wie einzelne Agenten, Tool-Aufrufe und ein

AI Gateways erklärt: Warum LLMs in Apps plötzlich Infrastruktur werden
Ein AI Gateway ist die zentrale Technik, die Anfragen an verschiedene große Sprachmodelle koordiniert und damit LLM‑Betrieb in Apps handhabbar macht. Das Stichwort AI Gateway

Warum LLMs bei langen Texten langsamer werden – wie KV‑Caching hilft
Längere Texte führen bei großen Sprachmodellen oft zu spürbar langsameren Antwortzeiten, weil das Modell für jedes neue Wort bereits erzeugte Informationen wiederholt verarbeitet. KV‑Caching reduziert
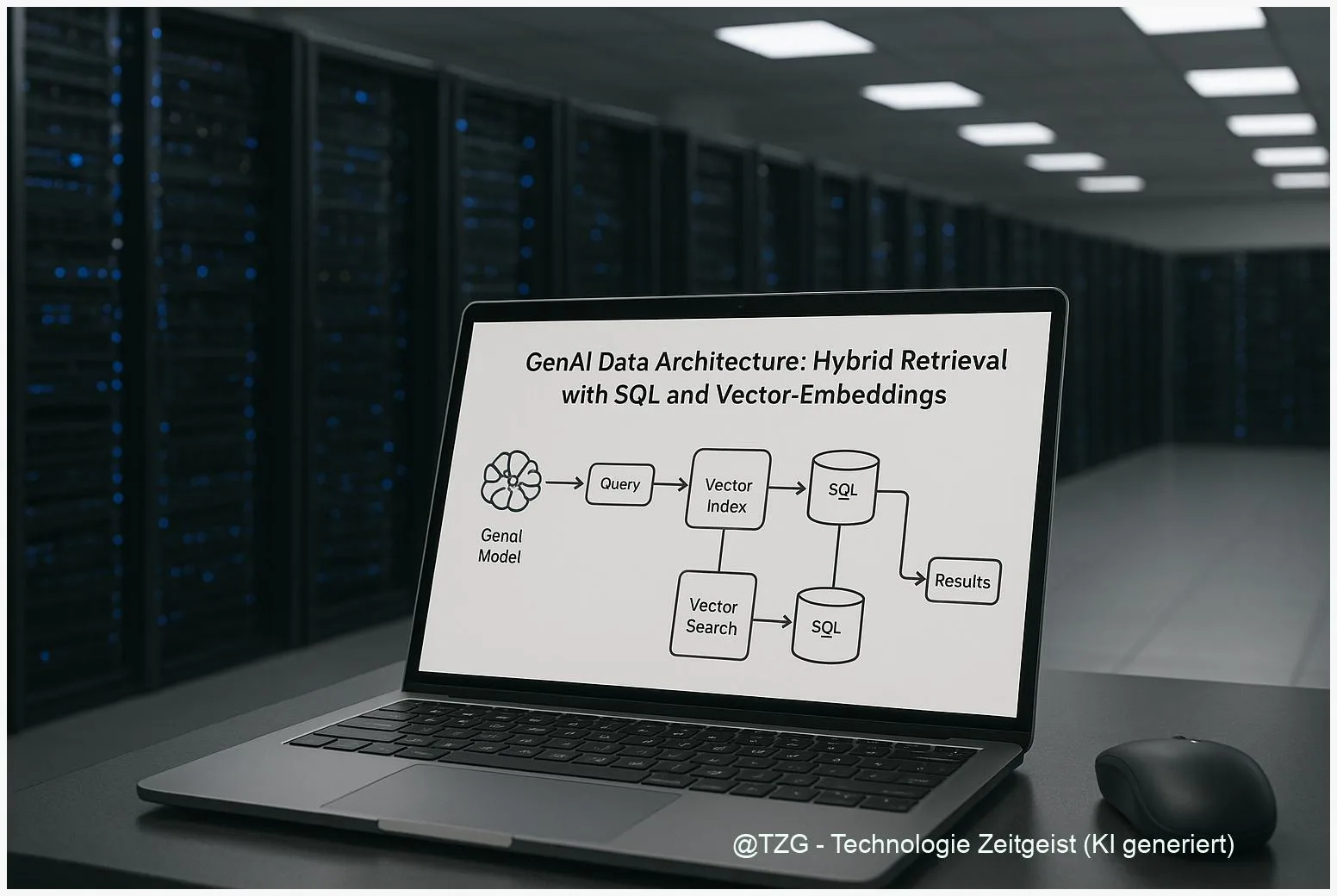
GenAI Datenarchitektur: Hybrid Retrieval mit SQL und Vector-Embeddings
Die GenAI Datenarchitektur entscheidet, wie Unternehmen Wissen verlässlich für generative Modelle abrufen. Hybrid Retrieval verbindet dichte Vector‑Embeddings mit klassischer SQL‑ oder Keyword‑Suche und reduziert so

RAG-Dokumentkompression: Effizient große Textsammlungen nutzen
RAG Dokumentkompression hilft, riesige Textbestände so zu verkleinern, dass semantische Suche und generative Modelle weiterhin korrekte Antworten liefern. In diesem Text steht, wie Produktquantisierung, semantische

Skalierbare AI‑Dokumentenpipeline: Architektur und praktische Anleitung
Eine skalierbare AI Dokumentenpipeline hilft, große Mengen an Texten zuverlässig zu durchsuchen, relevante Passagen zu finden und darauf basierend präzise Antworten zu erzeugen. Sie verbindet

RAG offline betreiben: So funktioniert ein lokales Retrieval‑System sicher
RAG offline betreiben bietet die Möglichkeit, große Textsammlungen lokal zur Beantwortung von Anfragen zu nutzen, ohne Referenzdaten an externe Anbieter zu schicken. Dieser Beitrag erklärt,

Transparente lokale LLM‑Pipelines mit Opik und Colocated Models
Zuletzt aktualisiert: 2025-11-22 Kurzfassung Opik local LLM pipeline ist heute ein pragmatischer Weg, um LLM‑Anwendungen lokal beobachtbar und reproduzierbar zu betreiben. Dieser Artikel zeigt, wie
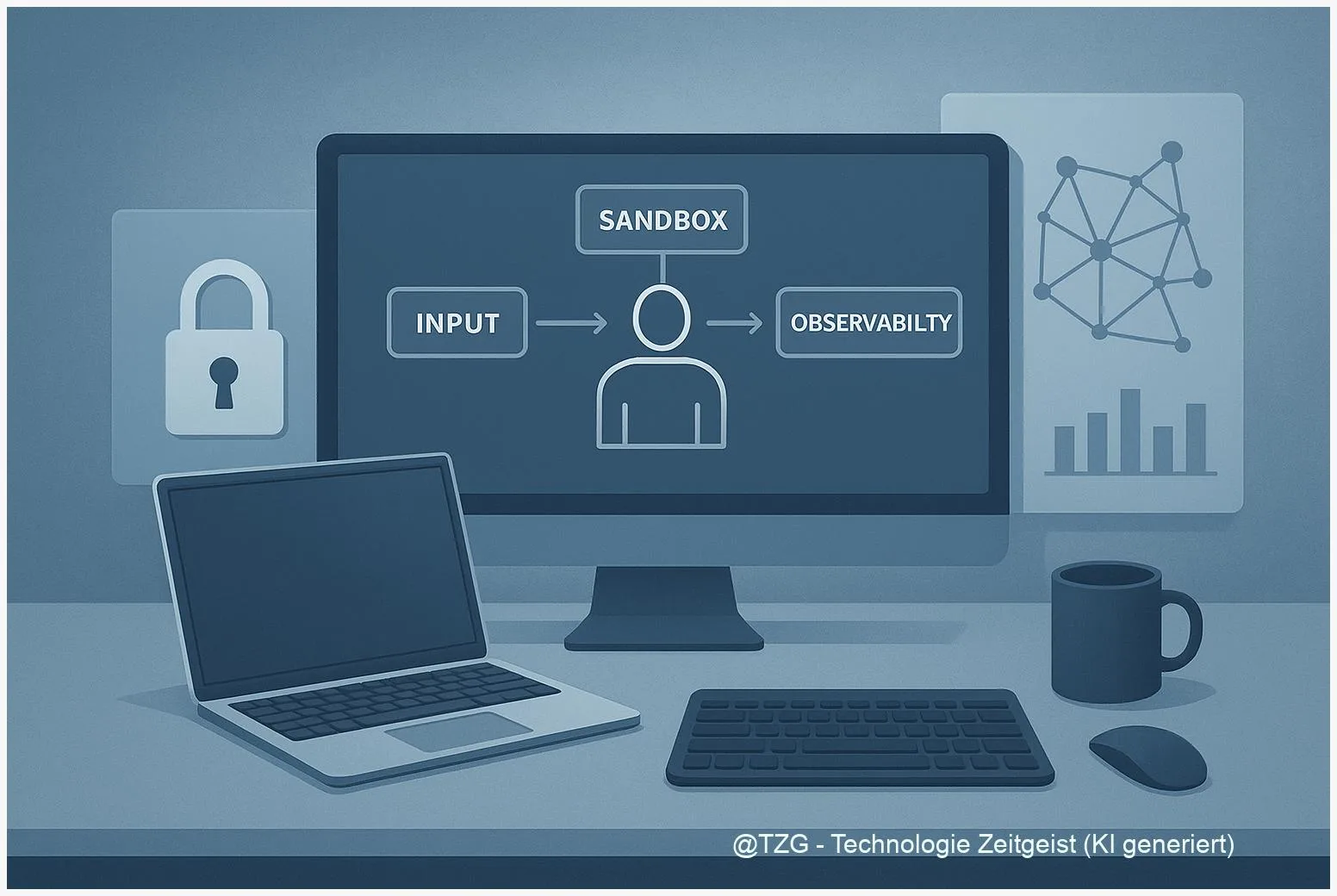
Privacy‑Guardrails für autonome Agenten: Input, Sandbox, Observability
Zuletzt aktualisiert: 2025-11-21 Kurzfassung Privacy‑Guardrails für autonome Agenten sind eine mehrschichtige Strategie: Input‑Filtering, Runtime‑Sandboxing, Policy‑Engines und Observability arbeiten zusammen, um Datenexfiltration, Prompt‑Angriffe und unerwünschte Aktionen
Zuverlässiges RAG-Database-Management für Enterprise Search
Zuletzt aktualisiert: 2025-11-20 Kurzfassung Ein praktischer Leitfaden zu RAG database management: Wie Unternehmen Retrieval‑Augmented‑Generation verlässlich betreiben, Quellen sauber nachverfolgen und Vector‑Datenbanken stabil skalieren. Der Text
Echtzeit‑Websuche für LLMs: Tavily und LangChain praktisch nutzen
Zuletzt aktualisiert: 2025-11-16 Kurzfassung Dieser Beitrag erklärt, wie Sie Echtzeit‑Websuche für LLMs mit Tavily und LangChain in zuverlässige RAG‑Pipelines überführen. Er zeigt zentrale API‑Bausteine, Integrationstipps,

Warum Lasttests bei KI versagen: Token‑Durchsatz, Confusion & Kontext
Zuletzt aktualisiert: 15. November 2025 Kurzfassung Klassische Lasttests messen oft nur Token‑Durchsatz. Wer aber sinnvolle AI‑Performance verstehen will, muss token throughput testing mit Wahrnehmungsmetriken koppeln:

ALRI und auditierbare Agenten: Log-Standards für Agentic AI
Zuletzt aktualisiert: 15. November 2025 Kurzfassung Auditierbarkeit ist kein Nice-to-have mehr. Dieser Text erklärt, wie das Konzept des Agentic Log Retention Index (ALRI) in praxisgerechte
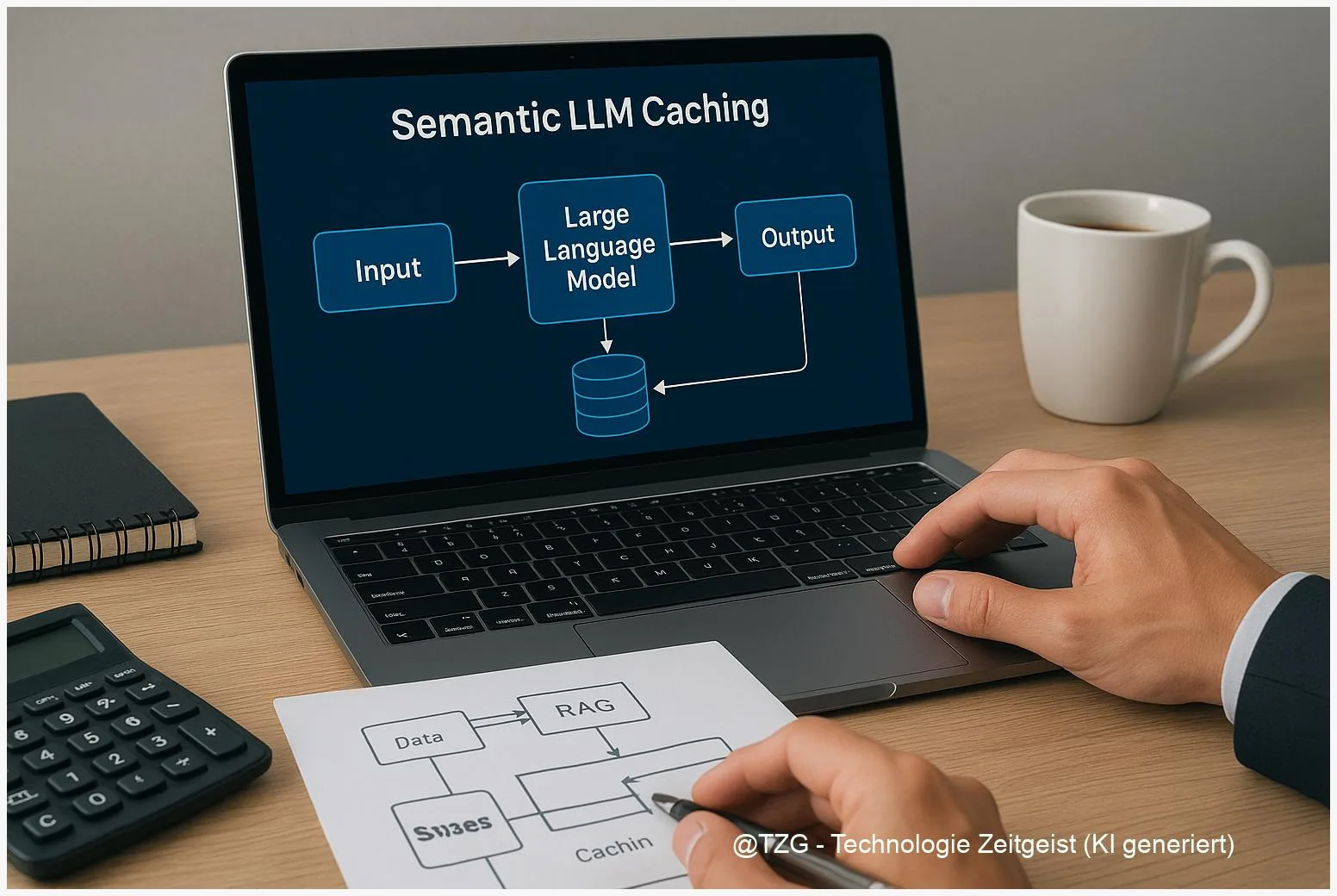
Semantic LLM Caching: RAG‑Latenz senken, API‑Kosten reduzieren
Zuletzt aktualisiert: 12. November 2025 Kurzfassung Dieser Text erklärt kompakt, wie semantic LLM caching in RAG‑Setups die Zeit bis zur Antwort verkürzen und API‑Kosten senken

MCP-Tool‑Bloat zu Skills: Agent‑Architektur für Kosten & Datenschutz
Zuletzt aktualisiert: 9. November 2025 Kurzfassung Tool‑Bloat in Agent‑Stacks kostet Zeit und Geld. Dieser Beitrag zeigt, wie “progressive tool discovery” hilft, den Prompt‑Overhead zu reduzieren