Kurzfassung
Dieser Text erklärt kompakt, wie semantic LLM caching in RAG‑Setups die Zeit bis zur Antwort verkürzen und API‑Kosten senken kann. Ich beschreibe, wie ein Cache mit Embeddings und ANN‑Lookup wirkt, welche Risiken es gibt und wie Prefix‑Caching sowie gelernte Eviction Strategien den Durchsatz stabilisieren. Am Ende steht eine pragmatische Roadmap für Produktionsteams, die wirklich arbeiten will.
Einleitung
Latency ist nicht nur eine technische Zahl — sie ist das Gefühl, das Nutzer haben, während sie warten. Wer mit Retrieval‑Augmented Generation (RAG) arbeitet, kennt den Spannungsbogen zwischen relevanter Antwort und der Zeit, die der LLM‑Call kostet. Dieser Artikel begleitet dich Schritt für Schritt durch eine pragmatische Strategie: wir legen eine semantische Zwischenschicht an, prüfen, wo Prefix‑Caching hilft, und zeigen, wie sich das alles verantwortbar in die Produktion bringen lässt.
Warum semantic LLM caching in Produktion Sinn macht
Viele Teams stoßen an denselben Punkt: die Antworten sind gut, aber teuer und manchmal träge. Ein semantischer Cache fängt genau dort an, wo Wiederholung und Nähe entstehen — nicht bei identischen Anfragen, sondern bei ähnlichen. Statt jede Anfrage neu an ein großes Modell zu schicken, wird die Nutzeranfrage als Vektor abgelegt und mit bestehenden Antworten abgeglichen. Trifft die Semantik zu, kann die vorherige Antwort wiederverwendet werden. Das spart API‑Aufrufe und Zeit, ohne die Qualität automatisch zu opfern.
Technisch klingt das simpel, aber die Praxis ist heikel. Einmal gespeicherte Antworten altern, Embedding‑Modelle ändern ihr Verhalten mit Updates, und ein zu großzügiger Similarity‑Threshold führt zu falschen Treffern. Deshalb ist ein Produktivsystem kein reiner Cache: es ist ein beobachtbares System mit Fallbacks—ein Platz, an dem Metriken und stichprobenhafte Mensch‑Checks den Unterschied machen.
“Caches sind keine Magie. Sie sind Verträge: du vertraust, dass das Vergangene noch nützlich ist. Unsere Aufgabe ist, das Vertrauen zu messen.”
Ein weiterer praktischer Punkt: Embedding‑APIs sind oft günstiger als komplette Prompt‑Calls. Wer die Kosten pro 1000 Tokens im Blick hat, kann mit einer frühen Embed‑First‑Strategie ökonomisch sinnvoll handeln — vorausgesetzt, die Hit‑Entscheidung ist robust. Deshalb ist semantic LLM caching für viele RAG‑Produkte ein Hebel mit unmittelbarer Wirkung, aber ohne sorgfältige Kontrolle auch ein Risiko.
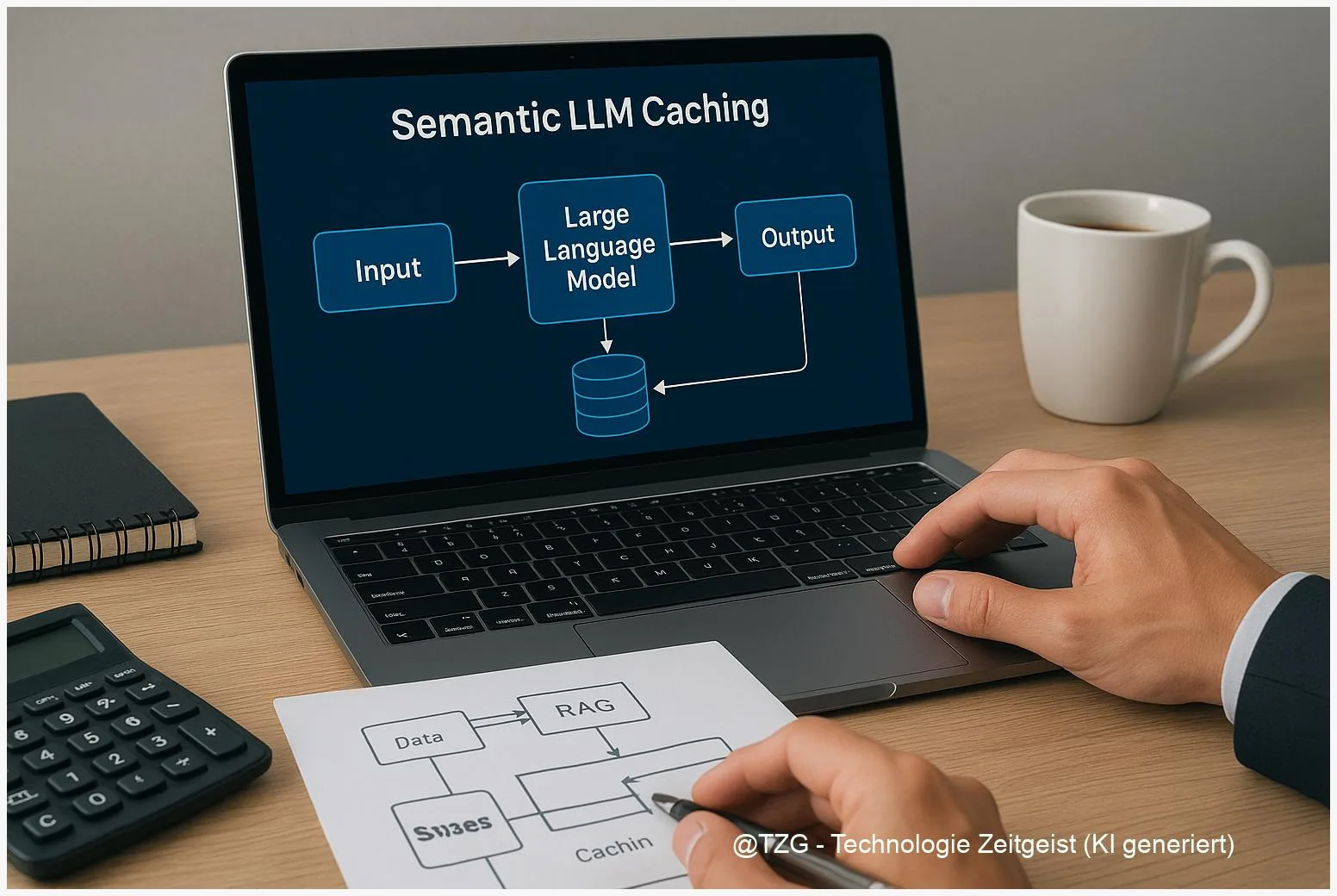
Wie ein praktischer Semantic‑Cache funktioniert
Die einfache Pipeline hat vier Schritte: Anfrage → Embedding → ANN‑Lookup → Entscheidung. Die Anfrage wird in einen Vektor umgewandelt, eine Approximate Nearest Neighbor (ANN) Suche findet ähnliche Einträge, und eine Policy entscheidet, ob ein Treffer confident genug ist, um die gecachte Antwort zurückzugeben. Fällt die Entscheidung negativ aus, läuft der normale RAG‑Pfad: Retrieval, Kontext‑Kombination, LLM‑Aufruf, und schlussendlich Speicherung des neuen Paares in den Cache.
Die Kunst liegt im Kalibrieren: Welches Embedding‑Modell wähle ich? Welcher similarity‑threshold ist passend? Die Praxis hat gezeigt, dass Baselines wie mpnet‑Varianten solide sind, aber ein kurzes A/B zur eigenen Datenbasis oft mehr bringt als eine generische Empfehlung. Wichtig ist, die Metriken richtig zu wählen: nicht nur Hit‑Rate, sondern “positive hit precision” — also wie oft ein Treffer qualitativ passt. Sampling‑Checks helfen hier enorm.
Annähernd alle produktiven Setups nutzen eine Kombination aus schneller ANN‑Vorfilterung (Faiss, HNSW, Qdrant, Pinecone) plus ein kleines Re‑Ranking auf dem Original‑Embedding für kritische Fälle. Die Indexparameter (z. B. efSearch oder nprobe) sind keine Schönheitsfehler — sie bestimmen, wie viel Abstand zwischen Geschwindigkeit und Recall besteht. Eine Faustregel: starte konservativ, messe p95‑Latenzen und optimiere schrittweise.
Schließlich zur Sicherheit: Cache‑TTL, Do‑Not‑Cache‑Listen (für PII) und konservative Eviction‑Regeln reduzieren Risiken. Wenn du anfangs eine conservative fallback‑Policy fährst — also bei Unsicherheit lieber das LLM neu befragst — schützt das nicht nur gegen Halluzinationen, sondern liefert auch Daten für bessere Thresholds.
Prefix‑Caching & gelernte Eviction
Prefix‑Caching zielt nicht auf die komplette Antwort, sondern auf interne Zustände des Decoders — die KV‑Arrays, die beim Dekodieren wiederverwendet werden können. In Chat‑Workloads, in denen viele Anfragen ähnliche System‑Prompts oder Verlaufsteile teilen, spart das Vorhalten dieser Prefix‑Zustände echte Dekodierkosten und reduziert Time‑to‑First‑Token.
Neue Arbeiten zeigen, dass eine einfache LRU‑Strategie oft reicht, um deutliche Verbesserungen zu erzielen. Gleichzeitig bringen gelernte Methoden wie “Learned Prefix Caching” (LPC) zusätzliche Effizienz: ein kleiner Prädiktor sagt die Wahrscheinlichkeit, dass ein Prefix erneut verwendet wird, und steuert Admission und Eviction. In Experimenten führte das zu spürbaren Einsparungen beim benötigten Cache‑Volumen und zu stabilerem Durchsatz — ein interessanter Hebel für Teams, die vLLM‑ähnliche Stacks betreiben.
Aber Vorsicht: gelernte Strategien brauchen Trainingsdaten, Überwachung und gelegentliche Retrainings. Wenn deine Produktion starken Lastwechseln oder Drift unterliegt, kann ein Predictor irreführend werden. Ergänze deshalb einfache Heuristiken: Tail‑Optimized LRU zur SLO‑Absicherung und Entropy‑Guided Budgeting für sehr lange Kontexte. So kombinierst du geringe Implementationskosten mit adaptiver Intelligenz.
Hardware‑ und Hosting‑Entscheidungen spielen hier eine Rolle: Managed‑APIs bieten meist weniger Zugang zu internen KV‑Zuständen, während Self‑Hosting oder vLLM‑Layer solche Optimierungen erst möglich machen. Für viele Teams ist die Balance: genug Infrastruktur, um Prefix‑Caching zu nutzen, aber nicht so komplex, dass Betriebskosten und Entwicklungsaufwand die Einsparungen auffressen.
Operationalisierung: Metriken und Roadmap
Um den Wert einer Caching‑Strategie zu messen, brauchst du mehr als nur „Hit‑Rate“. Metriken, die wirklich zählen: API‑Calls gespart pro Tag, p50/p95 Latenz, “positive hit precision” (qualitative Stichprobe der Treffer), Prefill‑Throughput für Prefix‑Caches, und die Kosten‑bilanz in deiner Währung. Instrumentiere Dashboards, die diese Metriken per Endpoint gruppieren — nur so siehst du, ob ein scheinbar hoher Hit‑Rate‑Wert wirklich Geld spart oder nur billige Fehltreffer produziert.
Eine pragmatische Roadmap sieht so aus: 30 Tage — Prototype: embed‑first Lookup mit Redis/Vector DB, einfache ANN‑Konfiguration, Baseline‑Metriken sammeln. 60 Tage — Index‑Sweeps (Faiss‑Parameter oder managed‑Konfigurationen), Threshold‑Kalibrierung per Held‑out Set, Re‑Ranking einführen. 90 Tage — Prefix‑Caching testen, gelernte Eviction in Staging evaluieren, A/B‑Tests mit echten Traces fahren und human‑in‑the‑loop Evaluationen etablieren.
Wichtige Fallstricke: ungefilterte PII in Caches, unbemerkte Drift des Embedding‑Modells nach Vendor‑Updates, sowie das stille Verlassen sich auf simulierte Timestamps in Papern. Gegenmaßnahmen sind klar: Do‑Not‑Cache Regeln, automatisierte Integrity Checks, und regelmäßige Stichproben‑Reviews. Zudem sollten SLOs abgesichert sein: Tail‑Optimized Eviction, conservative fallbacks und Alarmierung auf Anomalien.
Am Ende ist es ein iterativer Prozess. Beginne klein, miss oft, und skaliere, wenn die Daten zeigen, dass Treffer qualitativ passen. So wird aus einem technischen Patch ein verlässlicher Bestandteil deiner Produkt‑Experience.
Fazit
Semantic LLM Caching ist ein wirkungsvoller Hebel für RAG‑Produkte: weniger API‑Calls, geringere Latenz und oft bessere Nutzer‑Erfahrung. Erfolg hängt von sauberer Kalibrierung, Monitoring und verantwortlicher Governance ab. Prefix‑Caching und gelernte Eviction bieten zusätzliche Gewinne, sind aber betrieblich anspruchsvoller. Beginne mit einem kleinen Prototype, messe qualitativ und quantitativ, und erweitere Schritt für Schritt.
*Diskutiere deine Erfahrungen in den Kommentaren und teile den Artikel in deinen Netzwerken!*


Schreibe einen Kommentar