Q‑Learning einfach erklärt: Dieses Kurzabstract zeigt, wie ein Lernagent durch Versuch und Irrtum eine Aufgabe löst und welche Schritte ein kleines Gridworld‑Projekt für Einsteiger braucht. Der Text erklärt die wichtigsten Begriffe (Agent, Belohnung, Policy), gibt eine einfache Schritt‑für‑Schritt‑Anleitung für ein Mini‑Projekt und nennt typische Parameter wie Lernrate, Discount und Exploration. Wer nach einem praxisnahen Einstieg sucht, versteht danach, wie Q‑Learning in Lehrbeispielen funktioniert und wie sich Ergebnisse verlässlich prüfen lassen.
Einleitung
Viele Lernaufgaben lassen sich als Interaktion beschreiben: Ein Programm (Agent) trifft Entscheidungen in einer Umgebung und erhält Rückmeldungen in Form von Punkten oder Strafen. Diese Rückmeldungen definieren, was erfolgreich ist. Reinforcement Learning (RL) fasst genau dieses Lernprinzip zusammen und macht daraus Algorithmen, die durch Ausprobieren bessere Entscheidungen finden. Im Alltag begegnet das Prinzip etwa beim Navigieren einer App‑Navigation, beim automatisierten Spielen oder bei Empfehlungen, die sich an Nutzerreaktionen anpassen.
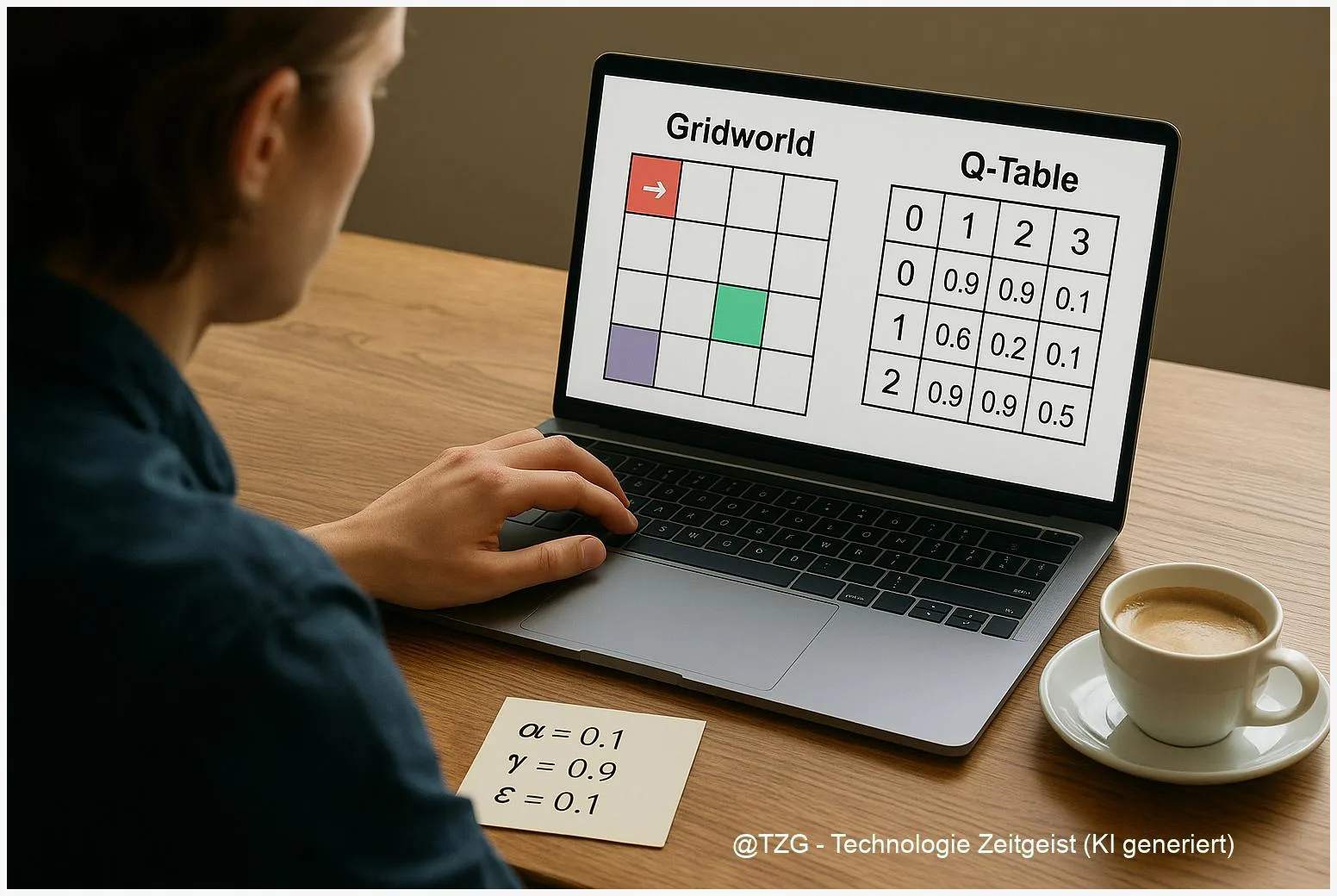
Für Einsteiger ist das klassische Gridworld‑Beispiel ideal: ein kleines Raster, ein Startpunkt, ein Ziel und einige Stolperfallen. Das Projekt ist überschaubar, benötigt nur Basis‑Python‑Kenntnisse und macht Lernschritte sichtbar. Dieser Artikel erklärt die Konzepte schrittweise, führt durch ein simples Mini‑Projekt und zeigt, worauf Sie bei Parametern und Auswertung achten sollten.
Was ist Reinforcement Learning in Kürze?
Reinforcement Learning beschreibt eine Lernform, bei der ein Agent anhand von Belohnungen und Strafen sein Verhalten verbessert. Vier zentrale Begriffe reichen, um das Grundbild zu verstehen: Zustand (wo sich der Agent befindet), Aktion (was er tut), Belohnung (Punkte, die er bekommt) und Policy (die Regel, nach der Aktionen gewählt werden). Eine Policy kann einfach eine Tabelle sein oder eine komplexe Funktion wie ein neuronales Netz.
Formal werden viele Probleme als Markov Decision Process (MDP) formuliert. Das bedeutet, die Entscheidung hängt nur vom aktuellen Zustand ab und nicht von der gesamten Vergangenheitsgeschichte. Diese Annahme vereinfacht die Modellierung und ist in vielen Lehrbeispielen gegeben. Wenn ein Problem nicht markovsch ist, braucht es zusätzliche Informationen.
RL ordnet Lernen als langfristige Erwartung von Belohnungen — nicht als unmittelbares Vorhersagen von Ergebnissen.
Methodisch unterscheidet man grob:
- Model‑based Methoden: Es gibt ein Modell der Umgebung und der Agent plant damit.
- Model‑free Methoden: Der Agent lernt direkt Werte oder Policies aus Erfahrungen, ohne ein Modell zu bauen. Q‑Learning ist ein klassisches model‑free Verfahren.
Für Einsteiger ist das Verständnis von Reward und Value wichtig: Reward ist die sofortige Rückmeldung, Value ist die erwartete Summe zukünftiger Rewards. Wer das unterscheidet, versteht auch, warum ein Agent kurzfristig Opfer bringt, um langfristig mehr zu gewinnen.
Die folgende Tabelle fasst gebräuchliche Parameter kurz zusammen.
| Parameter | Bedeutung | Typischer Bereich |
|---|---|---|
| Lernrate α | Wie stark neue Erfahrungen alte Schätzungen verändern | 0.01 – 0.5 |
| Discount γ | Gewichtung zukünftiger Belohnungen (0 = nur jetzt, 1 = Zukunft wichtig) | 0.9 – 1.0 |
| Exploration ε | Wahrscheinlichkeit, zufällig statt greedy zu handeln | 0.01 – 0.2 |
q‑learning einfach erklärt
Q‑Learning ist eine konkrete Methode, mit der ein Agent lernt, für jeden Zustand die besten Aktionen zu finden. Es ist tabellarisch und model‑free: In kleinen Umgebungen speichert der Agent eine Q‑Tabelle mit Werten Q(s,a). Diese Werte schätzen, wie gut es ist, in Zustand s die Aktion a zu wählen, unter Annahme, dass danach weiter optimal gehandelt wird.
Der Kern des Lernens ist eine einfache Aktualisierungsregel: Nach einer Aktion beobachtet der Agent die Belohnung r und den neuen Zustand s’. Die Q‑Tabelle wird nach der Formel angepasst:
Q(s,a) ← Q(s,a) + α [r + γ max_a’ Q(s’,a’) − Q(s,a)].
Diese Formel hat eine klare Intuition: Die neue Schätzung besteht aus der alten Schätzung plus einem Fehlerterm. Der Fehlerterm vergleicht die gerade beobachtete Belohnung plus den besten erwarteten zukünftigen Wert mit der bisherigen Schätzung. Lernrate α bestimmt, wie schnell die Tabelle reagiert; γ gewichtet die Zukunft.
Exploration ist in Q‑Learning wichtig. Ohne gelegentliches Ausprobieren (ε‑greedy: mit Wahrscheinlichkeit ε zufällige Aktion) bleibt der Agent möglicherweise in suboptimalen Gewohnheiten stecken. Typischer Ablauf eines Trainings ist: viele Episoden spielen, am Anfang viel explorieren und ε schrittweise verringern.
Q‑Learning hat einige praktische Vorzüge: Es ist einfach zu implementieren, robust in deterministischen kleinen Umgebungen und liefert oft schnell sichtbare Fortschritte. Grenzen zeigt es bei großen oder kontinuierlichen Zustandsräumen — dort ersetzt man die Tabelle durch Funktionen (z. B. neuronale Netze), was in den Deep‑RL‑Ansätzen passiert.
Wichtig: Die theoretischen Grundlagen von Q‑Learning reichen zurück bis zu der Arbeit von Watkins (1992). Für Grundlagen und didaktische Tiefe ist das Lehrbuch von Sutton & Barto eine sehr gute Referenz; die Ausgabe stammt aus 2018 und ist damit älter als zwei Jahre, bleibt aber als konzeptionelle Basis relevant.
Mini‑Projekt: Gridworld Schritt für Schritt
Ein einfaches Gridworld‑Projekt braucht nicht viel: ein zweidimensionales Raster (z. B. 5×5), Start‑ und Zielzellen, einige Hindernisse und eine Belohnungsstruktur. So gehen Sie vor:
- Umgebung definieren: Bestimmen Sie Größe, Start, Ziel, Schritt‑Kosten (z. B. −0.1 pro Schritt) und Belohnungen (z. B. +1 für Ziel, −1 für Falle). Die Umgebung kann deterministisch oder leicht zufällig sein.
- Q‑Tabelle initialisieren: Für jeden Zustand und jede Aktion Q(s,a)=0 oder kleine Zufallswerte setzen.
- Wähle ein Lernschema: Legen Sie α, γ, ε fest und entscheiden Sie, ob ε über die Zeit reduziert wird (ε‑Decay).
- Training: Spielen Sie viele Episoden. In jeder Episode wählt der Agent basierend auf ε‑greedy eine Aktion, erhält r, beobachtet s’ und aktualisiert Q(s,a). Beenden, wenn Agent das Ziel erreicht oder Max‑Schritte überschritten.
- Evaluation: Testen Sie die gelernte Policy ohne Exploration (ε=0) und messen Sie durchschnittliche Schritte bis zum Ziel und kumulierte Belohnung über mehrere Starts.
Praxis‑Tipps für stabile Ergebnisse:
- Verwenden Sie mehrere Trainingsläufe mit unterschiedlichen Zufallsinitialisierungen und mitteln Sie die Ergebnisse, statt nur einen Lauf zu prüfen.
- Visualisieren Sie die Policy als Pfeile im Grid und die Q‑Werte als Heatmap — das macht Lernfortschritt sofort sichtbar.
- Variieren Sie Parameter systematisch: halten Sie zwei fest und sweepen Sie den dritten. So erkennen Sie, welche Einstellungen robust funktionieren.
Typische Fehlerquellen sind eine zu hohe Lernrate (führt zu starkem Rauschen), zu wenig Exploration (keine besseren Wege gefunden) oder eine unglückliche Belohnungsstruktur (z. B. zu hohe Schritt‑Kosten). Deshalb sind kontrollierte Experimente mit festen Seeds und mehreren Runs wichtig.
Chancen, Risiken und praktische Tipps
Q‑Learning und RL bieten klare Chancen: für Lernaufgaben ohne explizites Trainingsset kann ein Agent autonom Strategien entwickeln. In Lehrkontexten sind diese Verfahren hervorragend geeignet, weil sie Intuition für Belohnungen, Exploration und Trade‑offs vermitteln. In der Praxis sind RL‑Methoden mittlerweile in Spielen, einfachen Robotikaufgaben und Empfehlungssystemen nützlich.
Risiken und Einschränkungen sind jedoch bedeutsam: RL ist oft datenhungrig und rechnet sich in komplexen, echten Umgebungen teuer. Deep‑RL‑Ansätze (Kombination aus RL und neuronalen Netzen) erweitern Fähigkeiten, vergrößern aber Rechenaufwand und tun sich mit Stabilität und Reproduzierbarkeit schwer. Diese Punkten werden in Übersichtsarbeiten zu Deep RL diskutiert (siehe Quellen).
Für eigene Experimente gilt: Beginnen Sie klein, messen Sie sorgfältig und dokumentieren Sie genau. Wichtige Prüfgrößen sind mittlere kumulierte Belohnung, Varianz über Läufe, und die Anzahl der Schritte bis zum Ziel. Wenn Sie RL in realen Systemen einsetzen, denken Sie an Sicherheit: Agenten können unerwartete Strategien finden, die formal eine Belohnung maximieren, aber sicherheitskritische Nebenwirkungen haben.
Weiterführende Schritte für Lernende:
- Erstellen Sie zuerst tabulare Beispiele (Gridworld, Cliff Walking) und verstehen Sie Konvergenzverhalten.
- Studieren Sie anschließend Grundlagen‑Texte wie Sutton & Barto (2. Auflage) für die mathematische Fundierung (Ausgabe 2018, daher älter als zwei Jahre).
- Für Anwendungen mit großen Zustandsräumen ergänzen Sie um Deep‑RL‑Übersichten aus 2018–2019, die gängige Architekturen und Limitierungen beschreiben.
So bleibt Ihr Lernen nachhaltig: Konzepte in kleinen Projekten anwenden, Ergebnisse dokumentieren und nach und nach komplexere Modelle ausprobieren.
Fazit
Q‑Learning ist ein klarer, praktischer Einstieg in Reinforcement Learning: Die Methode ist leicht implementierbar, erklärt zentrale Ideen wie Exploration vs. Exploitation und macht Lernverläufe sichtbar. Gridworld‑Mini‑Projekte sind ideal, um Konzepte zu üben, typische Parameter zu verstehen und solide Auswertungstechniken zu lernen. Wichtig bleibt, Ergebnisse über mehrere Läufe zu validieren und bei größeren Problemen auf funktionale Approximationen oder moderne Deep‑RL‑Methoden auszuweichen. So legen Sie ein robustes Verständnisfundament, auf dem komplexere Anwendungen sinnvoll aufbauen können.
Diskutieren Sie Ihre Erfahrungen mit kleinen RL‑Projekten in Kommentaren und teilen Sie den Artikel, wenn er Ihnen geholfen hat.


Schreibe einen Kommentar