Kurzfassung
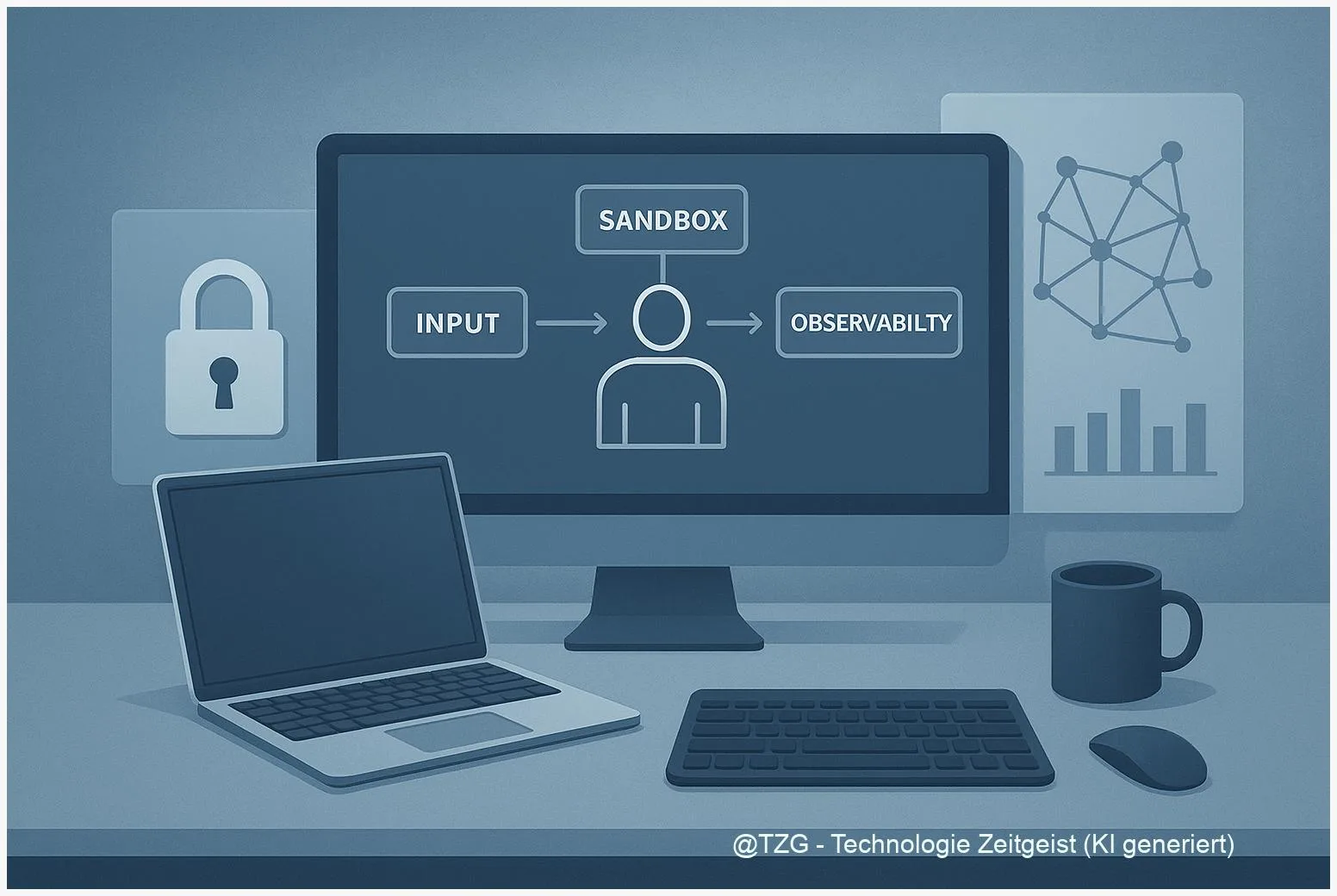
Privacy‑Guardrails für autonome Agenten sind eine mehrschichtige Strategie: Input‑Filtering, Runtime‑Sandboxing, Policy‑Engines und Observability arbeiten zusammen, um Datenexfiltration, Prompt‑Angriffe und unerwünschte Aktionen zu verhindern. Dieser Beitrag erklärt pragmatische Muster, die Sie sofort testen können, und verknüpft sie mit aktuellen Empfehlungen aus Forschung und Industrie.
Einleitung
Privacy‑Guardrails für autonome Agenten sind kein Luxus, sondern Betriebsstoff für verantwortungsvolle Systeme. Agenten, die eigenständig auf Daten zugreifen, Entscheidungen treffen oder Dienste ansteuern, eröffnen neue Chancen — und neue Risiken für Privatsphäre und Vertraulichkeit. In den folgenden Abschnitten erläutere ich pragmatische Schutzlagen: wie Eingangsfilter, Laufzeitisolierung, maschinenlesbare Policy‑Prüfungen sowie lückenlose Beobachtbarkeit zusammenwirken, um Risiken messbar zu reduzieren. Grundlage sind aktuelle Studien und Praxisberichte aus Forschung und Industrie.
Warum Privacy‑Guardrails heute wichtig sind
Autonome Agenten sind nicht mehr Zukunftsmusik: sie navigieren Daten, bauen Kontexte zusammen und veranlassen Aktionen. Genau das macht sie nützlich — und angreifbar. Forschung und Praxiserfahrungen zeigen: Prompt‑Injection, RAG‑Hygieneprobleme und unkontrollierte Tool‑Aufrufe können sensible Informationen nach außen tragen oder Systeme zu unerwünschten Aktionen verleiten. Die Debatte ist technisch, aber am Ende auch menschlich: Vertrauen entsteht nicht durch Versprechen, sondern durch nachweisbare Kontrollen und transparente Nachvollziehbarkeit.
„Guardrails sind weniger ein Hindernis als ein Vertrag zwischen Maschine und Betreiber: sie definieren, was getan werden darf — und wie man Verletzungen erkennt.“
Praktisch bedeutet das: Schutz darf nicht aus einer einzigen Technik bestehen. Stattdessen empfiehlt sich ein mehrschichtiger Aufbau. Erste Schichten filtern Eingaben und erkennen Geheimnisse, mittlere Schichten begrenzen Auswirkung und Rechte von Tools, während höhere Schichten Entscheidungen auditierbar machen und Menschen bei kritischen Fällen einschalten. Ein solcher Ansatz ist robust gegen einfache Attacken und skaliert mit wachsender Komplexität der Agenten.
Die Praxis zeigt zudem: ohne Observability bleibt jede Forensik blind. Traces, strukturierte Logs und semantische Metriken sind notwendig, um Fehlverhalten zu erklären und regulatorische Anforderungen zu erfüllen. Im Verlauf dieses Artikels erläutere ich konkrete Muster, die sich derzeit in Forschung und Industrie als praktikabel erweisen.
Tabellen sind nützlich, um Schutzschichten zu vergleichen:
| Guardrail | Zweck | Einschätzung |
|---|---|---|
| Input‑Filtering | Erkennung und Block von schädlichen Eingaben | Hoch |
| Sandboxing | Begrenzung des Zugriffs auf Systeme | Moderat–Hoch |
Input‑Filtering: Erste Verteidigungslinie
Input‑Filtering ist die unmittelbarste und oft effektivste Schicht: bevor ein Agent einen Prompt an ein LLM sendet oder eine externe Datenquelle indiziert wird, sollten Inhalte geprüft und bereinigt werden. Das umfasst einfache Regeln wie Regex‑Scanner für Secrets ebenso wie semantische, ML‑gestützte Detektoren für verschleierte oder multilingual formulierte Angriffe. Die Kombination aus syntaktischer Erkennung und semantischer Bewertung erhöht die Trefferquote ohne die Nutzererfahrung unnötig zu belasten.
Wichtig ist die Trennung von vertrauenswürdigen und untrusted Kontexten. Inhalte aus unbekannten Quellen, vom Nutzer hochgeladene Dokumente oder extern geladene Webseiten sollten einer härteren Härtung unterliegen: HTML‑Sanitizer, Dateityp‑Checks, Entpackungsregeln und vor allem eine Vetting‑Pipeline für RAG‑Ingestion. Das reduziert das Risiko, dass schadhafte Anweisungen unbemerkt in den Kontext gelangen.
Technische Zusatzmaßnahmen haben sich als nützlich erwiesen: Secret‑Scanner identifizieren Schlüssel und Tokens vor dem Indexieren, und Konzepte wie signierte System‑Prompts („Signed‑Prompt“) können systemkritische Anweisungen vor Manipulation schützen. Solche Ansätze sind keine Allheilmittel, aber sie erhöhen die Schwierigkeit eines erfolgreichen Angriffs deutlich.
Operativ sollten Teams ein Playbook einführen: automatisierte Tests (Red‑Teaming), Logging der Input‑Transformationsschritte und Metriken für False‑Positives/-Negatives. Regelmäßiges Testen mit bekannten Exploit‑Kits und das Monitoring von Alerts hilft, die Filter an reale Umgehungsversuche anzupassen.
Zusammengefasst: Input‑Filtering ist nicht nur Technik, sondern Prozess. Es verlangt klare Regeln, automatisierte Kontrollen und eine Feedback‑Schleife, damit Filter wirksam bleiben, während Agenten produktiv bleiben.
Sandboxing & Policy‑Engines zur Laufzeitkontrolle
Wenn Input‑Filter die Eintrittskontrolle sind, dann sind Sandboxing und Policy‑Engines die Laufzeitgrenzen. Sandboxing isoliert Tools und Prozesse: Container, restriktive Filesystem‑Policies oder Netzwerk‑Whitelists begrenzen, was ein Agent tatsächlich anstellen kann. Weniger Rechte bedeuten einen kleineren Schaden, selbst wenn ein Agent kompromittiert wird.
Policy‑Engines wie Open Policy Agent (OPA) haben sich als pragmatische Lösung für Entscheidungslogik bewährt. Sie ermöglichen, Regeln als Code zu pflegen und zur Laufzeit zu evaluieren: darf ein Agent eine externe API ansprechen, darf er eine Datei schreiben, darf ein Ergebnis exportiert werden. Ein zentraler Vorteil ist Auditierbarkeit: Entscheidungen werden strukturiert protokolliert, was regulatorische Anforderungen und forensische Analysen erleichtert.
Technisch empfiehlt sich ein hybrider Einsatz: ein externer Policy Decision Point (PDP) liefert zentrale Entscheidungen, ein lokaler Policy Enforcement Point (PEP) mit Caching reduziert Latenz in Echtzeitschleifen. Studien und Experimente aus 2024–2025 zeigen, dass Runtime‑Enforcement praktikabel ist, wenn Architektur und Caching‑Strategien bedacht sind.
Wichtig ist das Design von Default‑Verhalten: für kritische Pfade sollte das System im Zweifel blocken oder eine menschliche Prüfung anstoßen. Ebenso nützlich sind strukturierte Policy‑Kataloge (Policy‑Cards), die wiederverwendbare Regeln enthalten: etwa „keine externe PII‑Exfiltration“ oder „keine Codeausführung ohne Sandbox“. Solche Regeln lassen sich automatisiert testen und versionieren, was Governance und Compliance stärkt.
Praxis‑Tipp: starten Sie mit einem kleinen Regelset für risikoreiche Aktionen, messen Sie Latenz und Fehlalarme und iterieren Sie. So wachsen Policy‑Engines mit dem System, statt es zu blockieren.
Observability, Output‑Validation und Human‑in‑the‑Loop
Ohne Beobachtbarkeit bleibt jede Sicherheitsmaßnahme schwer zu bewerten. Agent‑spezifische Observability — oft als AgentOps bezeichnet — erfordert strukturierte Spans für Agent, Plan, Task, Tool und Policy‑Events. Solche Traces machen Entscheidungen nachvollziehbar und ermöglichen es, Ausreißer, Entgleisungen oder wiederkehrende Muster zu identifizieren.
Output‑Validation ist die letzte Barriere vor der Übergabe an Nutzer oder Systeme. Sie prüft, ob Ergebnisse in erwarteten Schemata vorliegen, ob sie sensible Informationen enthalten und ob Provenance‑Metadaten (Quelle, Retrieval‑Kontext) vorhanden sind. Deterministische Post‑Filter, Schema‑Checks oder „provenance stickers“ helfen, Halluzinationen und versehentliche Datenleaks zu reduzieren.
Human‑in‑the‑Loop (HITL) bleibt unverzichtbar für risikoreiche Pfade: rechtliche Entscheidungen, finanzielle Transaktionen oder Aktionen mit hoher Reichweite sollten eskalieren. Wichtig ist dabei ein klares Design: welche Ereignisse triggern eine Eskalation, wie lange darf der Mensch prüfen, und welche SLAs gelten. Embedding solcher Regeln in Observability‑Dashboards macht den Prozess messbar und wiederholbar.
Operational gesehen empfiehlt sich ein Monitoring‑Set aus semantischen Indikatoren (z. B. Tool‑Aufrufhäufigkeit, Plan‑Branching‑Komplexität, Guardrail‑Trigger), klassischen Systemmetriken und Incident‑Logs. Regelmäßige Post‑mortems, Red‑Teaming und forensische Audits schließen den Zyklus: sie zeigen, ob Guardrails wirken und wo Anpassungen nötig sind.
In Summe: Observability macht Guardrails wirksam — sie liefert die Daten, um Regeln zu überprüfen, Vorfälle zu analysieren und Vertrauen gegenüber Nutzerinnen und Regulatoren zu belegen.
Fazit
Privacy‑Guardrails für autonome Agenten brauchen mehrere, aufeinander abgestimmte Schichten: Vorprüfung der Eingaben, Laufzeitgrenzen durch Sandboxing, maschinenlesbare Policy‑Entscheidungen und lückenlose Beobachtbarkeit. Keines dieser Elemente genügt allein. Zusammen liefern sie Nachvollziehbarkeit, messbare Sicherheit und Handlungspfad für Eskalationen.
Die technische Umsetzung ist heute praktikabel: bewährte Tools für Policy‑Enforcement, Input‑Scanning und Agent‑Observability existieren und lassen sich in Pilotprojekten erproben. Entscheidend bleibt der Prozess: testen, messen, anpassen.
Wer Agenten produktiv einsetzt, sollte mit kleinen, risikoorientierten Schritten beginnen — und Guardrails nicht als Hindernis, sondern als Vertrauensinstrument begreifen.
*Diskutieren Sie Ihre Erfahrungen mit Privacy‑Guardrails in den Kommentaren und teilen Sie diesen Beitrag, wenn er hilfreich war.*
Schreibe einen Kommentar