Kurzfassung
Dieses Playbook zeigt, wie Sie Gender‑Bias in Empfehlungssystemen entdecken und messen können — mit Fokus auf Embeddings und latent‑factor Modelle. Es beschreibt praxisnahe Richtungs‑Methoden (Centroid, SVC, PCA), erklärt EAA/DEAA/R‑RIPA‑Tests und führt durch Permutationstests sowie einfache Klassifikationschecks. Ziel: robuste Audit‑Entscheidungen treffen und erste, evaluierbare Gegenmaßnahmen planen.
Einleitung
Embeddings sind die leisen Architekten unserer Empfehlungen: kompakte Zahlenräume, in denen Vorlieben und Muster sitzen. Genau hier kann sich Gender‑Bias in Empfehlungssystemen einnisten — oft unsichtbar, weil das explizite Merkmal entfernt wurde. Dieser Text ist ein praktisches Audit‑Playbook: keine Theorien, sondern Schritte, Tests und handhabbare Werkzeuge, damit Teams schnell prüfen, ob und wie stark sensitive Attribute im latenten Raum verankert sind. Wir stützen uns auf etablierte Untersuchungen (u. a. ACL 2021; arXiv 2023) — Hinweis: einige Quellen haben einen Datenstand, der älter als 24 Monate ist.
Warum Embeddings Gender kodieren
Embeddings entstehen aus Nutzersignalen: Klicks, Streams, Käufe. Sie komprimieren diese Verhaltensströme in Vektoren, die Gemeinsamkeiten und Unterschiede mathematisch widerspiegeln. Wenn Verhaltensmuster zwischen Gruppen systematisch verschieden sind — etwa unterschiedliche Genre‑Vorlieben, Aktivitätszeiten oder Social‑Signals — dann speichert der latente Raum diese Muster. Das ist kein moralisches Urteil, sondern eine statistische Tatsache: Modelle optimieren Vorhersagefehler, nicht Gerechtigkeit.
Warum heißt das ein Problem? Weil Empfehlungssysteme Entscheidungen treffen: wen sie sichtbar machen, welche Inhalte verstärkt werden. Wenn ein Item‑Embedding stark mit der Richtung „männlich“ oder „weiblich“ korreliert, bedeutet das, dass Menschen eines bestimmten Geschlechts wahrscheinlicher mit bestimmten Inhalten konfrontiert werden — unabhängig von ihren individuellen Präferenzen. Praktisch: eine Podcast‑Kategorie, die tendenziell männlich kodiert ist, erhält höhere Sichtbarkeit bei Nutzern mit ähnlicher Vector‑Projektion.
Wichtig ist die Unterscheidung zwischen expliziter und impliziter Repräsentation. Explizit ist ein Gender‑Feature, das im Training auftaucht; implizit sind Korrelationen, die aus Verhalten, Popularität und gemeinsamen Item‑Interaktionen entstehen. Studien zeigen immer wieder: Entfernen des expliziten Gender‑Features reduziert Bias‑Signale, beseitigt sie aber nicht zwingend (siehe arXiv 2023). Das heißt: Auditarbeit muss tiefer gehen als simples Feature‑Dropping.
„Ein Embedding spiegelt, was es gelernt hat — nicht, was wir wollen, dass es gelernt hätte.”
Für Audits bedeutet das: nicht nur nach dem offensichtlichen Auslöser suchen, sondern systematisch fragen, welche Signale indirekt Gleiches kodieren können — und welche Mechanismen die Amplifikation verstärken können: Popularitätsfeedback, cold‑start‑Effekte oder cross‑feature Interaktionen.
Audit‑Toolkit: Richtungen, Metriken, Tests
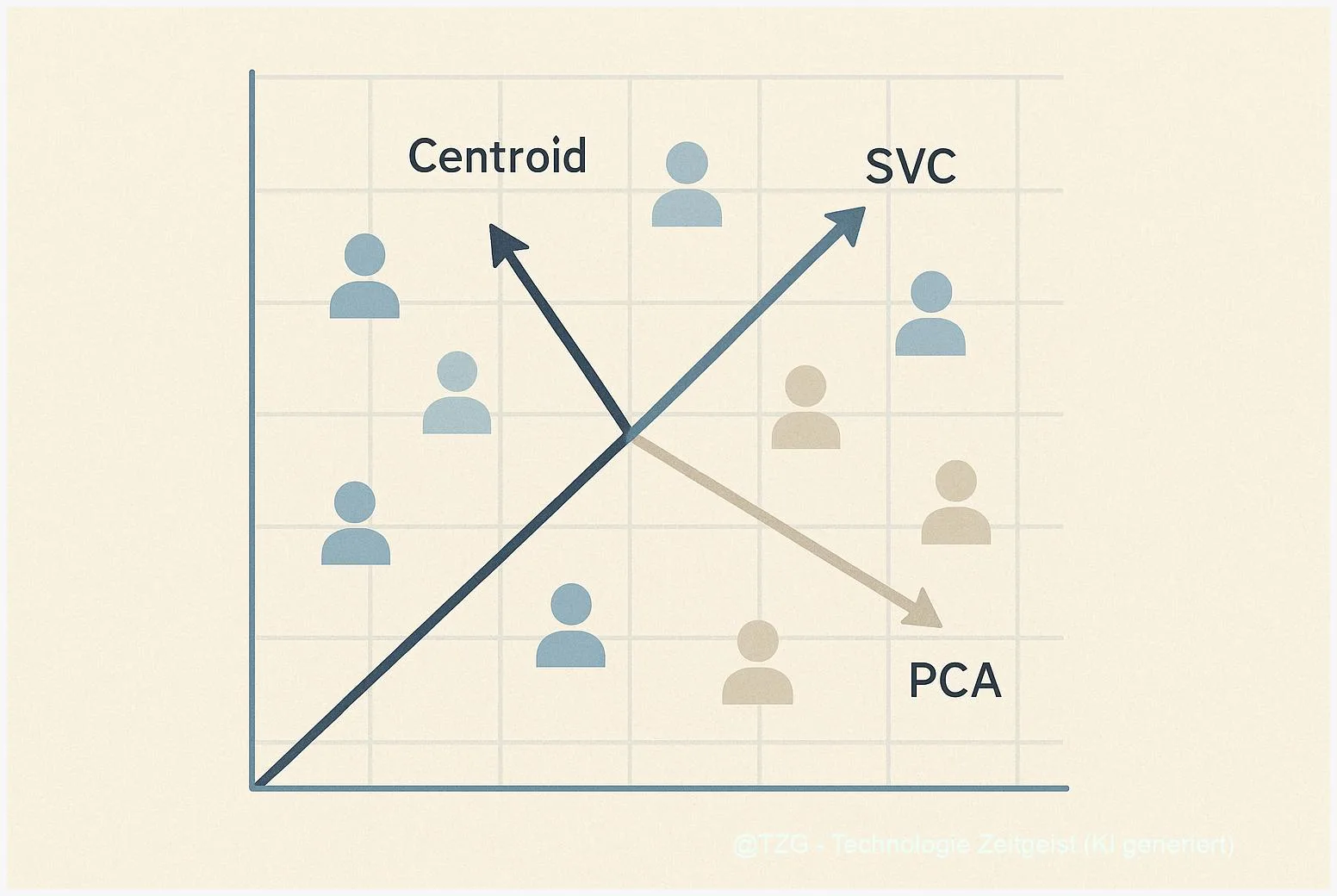
Ein robustes Audit kombiniert Visualisierung, mehrere Bias‑Richtungen und statistische Tests. Drei Richtungs‑Methoden haben sich in der Praxis bewährt:
- Centroid‑Differenz: Mittelvektor einer Gruppe minus Mittelvektor der Gegengruppe. Einfach zu rechnen, konservativ in der Interpretation — gut als erstes Signal.
- SVC‑Richtung: Trainingsgewichte eines linearen Support‑Vector‑Classifier zwischen Gruppen. Sensibler und oft stabil, liefert eine trennende Achse, ist aber abhängig von Datensplits und Regularisierung.
- PCA‑/Pair‑Richtung: Hauptkomponenten aus gepaarten Unterschieden. Mächtig, aber empfindlich an Paarwahl — diese Methode verlangt besonders strenge Robustheits‑Checks.
Auf diesen Richtungen bauen Metriken wie EAA (Entity Attribute Association), GEAA (Group EAA) und DEAA (Differential EAA) auf: sie messen, wie stark Item‑ oder User‑Vektoren in Richtung eines Attributs projizieren. Die adaptierte R‑RIPA‑Metrik überträgt RIPA‑Ideen aus NLP in Recommender‑Settings und erlaubt relationale Tests — jedoch ist R‑RIPA sehr sensitiv gegenüber der gewählten Bias‑Richtung und sollte nur mit validierten Achsen genutzt werden (arXiv 2023).
Statistik ist entscheidend: Permutationstests (Shuffle‑Labels) liefern p‑Werte für beobachtete Effekte; Bootstrap‑Resamples zeigen Konfidenzintervalle für Richtungen. Empirische Praxis: niemals nur ein Maß berichten. Vergleichen Sie Centroid, SVC und PCA; zeigen Sie Varianz über Seeds und Subsamples. Wenn nur eine Methode signifikant ist, ist Vorsicht angebracht — das kann ein Artefakt der Stichprobe sein.
Praktisch hilfreich sind außerdem einfache Klassifikationschecks: Trainieren Sie einen linearen Classifier auf User‑Embeddings, um das sensitive Attribut vorherzusagen. Hohe Vorhersagegenauigkeit (> zufällig) signalisiert, dass das Attribut im latenten Raum repräsentiert ist — und damit potenziell amplifiziert werden kann, wenn das Empfehlungssystem Entscheidungen entlang ähnlicher Mechaniken trifft.
Step‑by‑Step Playbook zur Entdeckung & Messung
Dieses Kapitel ist die Checkliste, mit der Sie in wenigen Stunden ein aussagekräftiges Audit durchführen können. Jedes Schritt‑Paar enthält ein kurzes Ziel und die erwartete Ausgabe.
- Datensnapshot & Versionierung: Ziel: nachvollziehbare Audit‑Basis. Ausgabe: Versionierte Embeddings, Random‑Seed, Datumsstempel. Dokumentieren Sie, welche Nutzer‑ und Item‑Subset‑Filter eingesetzt wurden.
- Explorative Visualisierung: Ziel: erstes Gefühl für Gruppentrennung. Ausgabe: PCA‑Plots (1./2. Komponente) für User‑ und Item‑Embeddings, farbkodiert nach Attributen.
- Richtungen berechnen: Ziel: mindestens drei Achsen (Centroid, SVC, PCA‑pairs). Ausgabe: normalisierte Richtungsvektoren mit Speicherversion.
- Intrinsic‑Metriken: Ziel: EAA/GEAA/DEAA pro Richtung. Ausgabe: Effektgrößen + Permutation‑p‑Werte (z. B. 10k Shuffles) und Bootstrap‑CIs.
- Klassifikations‑Explainer: Ziel: prüfen, ob Embeddings sensitive Attribute vorhersagen. Ausgabe: Accuracy, Precision/Recall pro Subgruppe; Feature‑Importance (bei linearer LogReg/SVC) zeigt Richtungssensitivität.
- Robustheitsmatrix: Ziel: Stabilitätsbewertung. Ausgabe: Tabelle der Ergebnis‑Varianz über Seeds, Subsamples, Paar‑Sets; markieren Sie konsistente Signals.
Interpretationsregel: Beurteilen Sie Effekte nach zwei Dimensionen — statistisch (p‑Wert) und praktisch (Operational Impact). Ein kleiner, aber konsistenter DEAA kann in sensiblen Kontexten ausreichend sein, um Governance‑Massnahmen auszulösen. Dokumentieren Sie Schwellen, z. B. p<0.01 plus Effektgröße oberhalb eines organisationsspezifischen Werts.
Beispielworkflow in 90 Minuten (Schnellcheck): 1) lade 10k User‑Embeddings + 1k Item‑Embeddings; 2) PCA‑Plot; 3) Centroid + SVC Richtungen; 4) EAA/DEAA + 1k Permutation; 5) kurzer Klassifikator. Ergebnis: Flag oder No‑Flag mit Begründung.
Wichtig: Studien zeigen, dass diese Verfahren unterschiedlich ausfallen können (ACL 2021; arXiv 2023) — Reproduzierbarkeit heißt mehrere Methoden, Seeds und dokumentierte Entscheidungen. Viele Befunde in der Literatur haben einen Datenstand älter als 24 Monate; behandeln Sie daher Benchmarks als Orientierung, nicht als Gesetz.
Gegenmaßnahmen & Monitoring
Audit ist nur der Anfang. Wenn Sie eine problematische Association finden, folgt die schwierige Phase: Abwägen von Maßnahmen gegen Nutzwertverlust. Es gibt kein One‑Size‑Fits‑All; meist lohnt ein Kombinationsansatz.
Typische Maßnahmen im Überblick:
- Feature‑Removal: das explizite Attribut streichen. Effekt: oft nützlich, aber selten vollständig — implizite Signale bleiben.
- Re‑weighting / Resampling: Trainingsdaten so gewichten oder sampeln, dass Gruppen gleichmäßiger vertreten sind. Effekt: reduziert Korrelationen, kann aber Utility‑Verlust oder Overfitting erzeugen.
- Adversarial‑Debiasing / INLP: Repräsentationen so anpassen, dass sensitive Richtungen neutralisiert werden. Effekt: wirkungsvoll für lineare Anteile, riskiert Informationsverlust.
- Exposure‑Balancing: Ranking‑ oder Re‑ranking‑Layer, die Sichtbarkeit über Gruppen ausgleichen, ohne die Embeddings direkt zu verändern.
Empfehlung: A/B‑getestete Kombinationen. Beispiel: Feature‑Removal + Re‑weighting prüfen, dann Exposure‑Balancing upstream schalten. Immer messen: (a) downstream Utility (z. B. CTR, Retention), (b) Verstärkungs‑Risiken (amplification) mittels Simulationen, (c) fairness‑Metriken (DEAA/EAA nach Maßnahme).
Monitoring ist essentiell: Versionieren Sie Metriken (DEAA zeitreihe pro Release), und konfigurieren Sie Alerting (z. B. p<0.01 && Effekt>X über zwei Releases). Legen Sie Governance‑Schwellen fest, und definieren Sie Verantwortlichkeiten: wer analysiert, wer entscheidet über Interventionen.
Schließlich: Transparenz. Dokumentieren Sie Entscheidungen und kommunizieren Sie Trade‑offs intern. Ein gutes Audit‑Protokoll ist weniger ein Fingerzeig auf Fehler als ein Arbeitsbuch für kontinuierliche Verbesserungen.
Fazit
Embeddings können Gender‑Assoziationen enthalten — auch wenn das explizite Merkmal entfernt wurde. Ein belastbares Audit nutzt mehrere Richtungen (Centroid, SVC, PCA), kombiniert EAA/DEAA/R‑RIPA‑Tests und prüft Robustheit über Seeds und Subsamples. Maßnahmen sollten A/B‑getestet und auf Utility‑Tradeoffs geprüft werden. Dokumentation und Monitoring machen das Ergebnis handhabbar und steuerbar.
*Diskutiert eure Erfahrungen mit Embedding‑Audits in den Kommentaren und teilt diesen Beitrag in den sozialen Medien!*



Schreibe einen Kommentar