Kurzfassung
Dieses Stück liefert ein praktisches Playbook zur Erstellung einer GenAI incident severity matrix für SOCs und Incident‑Response‑Teams. Es erklärt die Dimensionen, ein nachvollziehbares Scoring, Integrationspunkte in bestehende Triage‑Workflows und prüfbare Validierungs‑Schritte. Der Fokus liegt auf operabler Umsetzbarkeit, ohne normative Dogmen — damit Teams schnell priorisieren, kommunizieren und handeln können.
Einleitung
Genau dann, wenn Modelle beginnen, Entscheidungen zu treffen, braucht ein SOC eine einfache, verlässliche Methode, um Vorfälle einzuordnen. Eine GenAI incident severity matrix bietet genau das: ein praktisches Raster, das technische Indikatoren, Daten‑ und Modell‑Integrität sowie Business‑ und Safety‑Folgen zusammenführt. Dieser Artikel zeigt, wie sich solche Matrizen aus international anerkannten Frameworks ableiten lassen und wie Teams daraus klare Playbooks für Erkennung, Eskalation und Reporting formen.
Warum eine GenAI Incident Severity Matrix nötig ist
Traditionelle Incident‑Kategorien reichen nicht aus, wenn ein Vorfall das Zusammenspiel aus Trainingsdaten, Modellgewichten und Live‑Outputs betrifft. Ein Datenleck, ein gezieltes Poisoning oder ein manipulierter Prompt können ähnliche Symptome zeigen, aber völlig unterschiedliche Reaktionspfade erfordern. Die Severity‑Matrix übersetzt technische Beobachtungen in handlungsfähige Prioritäten: Was sofort isoliert werden muss, was überwacht werden kann und was externe Meldungen oder regulatorische Schritte notwendig macht.
“Priorität entsteht nicht aus Lautstärke, sondern aus Konsequenz. Eine Matrix macht die Konsequenz sichtbar.”
Eine gut gestaltete Matrix verhindert zweierlei Fehler: Erstens die Unterreaktion bei latenten Modell‑Schäden, zweitens das Over‑Escalation‑Szenario, das Ressourcen bindet. In beiden Fällen kosten Fehlentscheidungen Zeit, Reputation und im schlimmsten Fall Menschenleben. Daher verbindet die Matrix technische Metriken mit Business‑ und Safety‑Indikatoren und gibt klare Cutoffs für Eskalation vor.
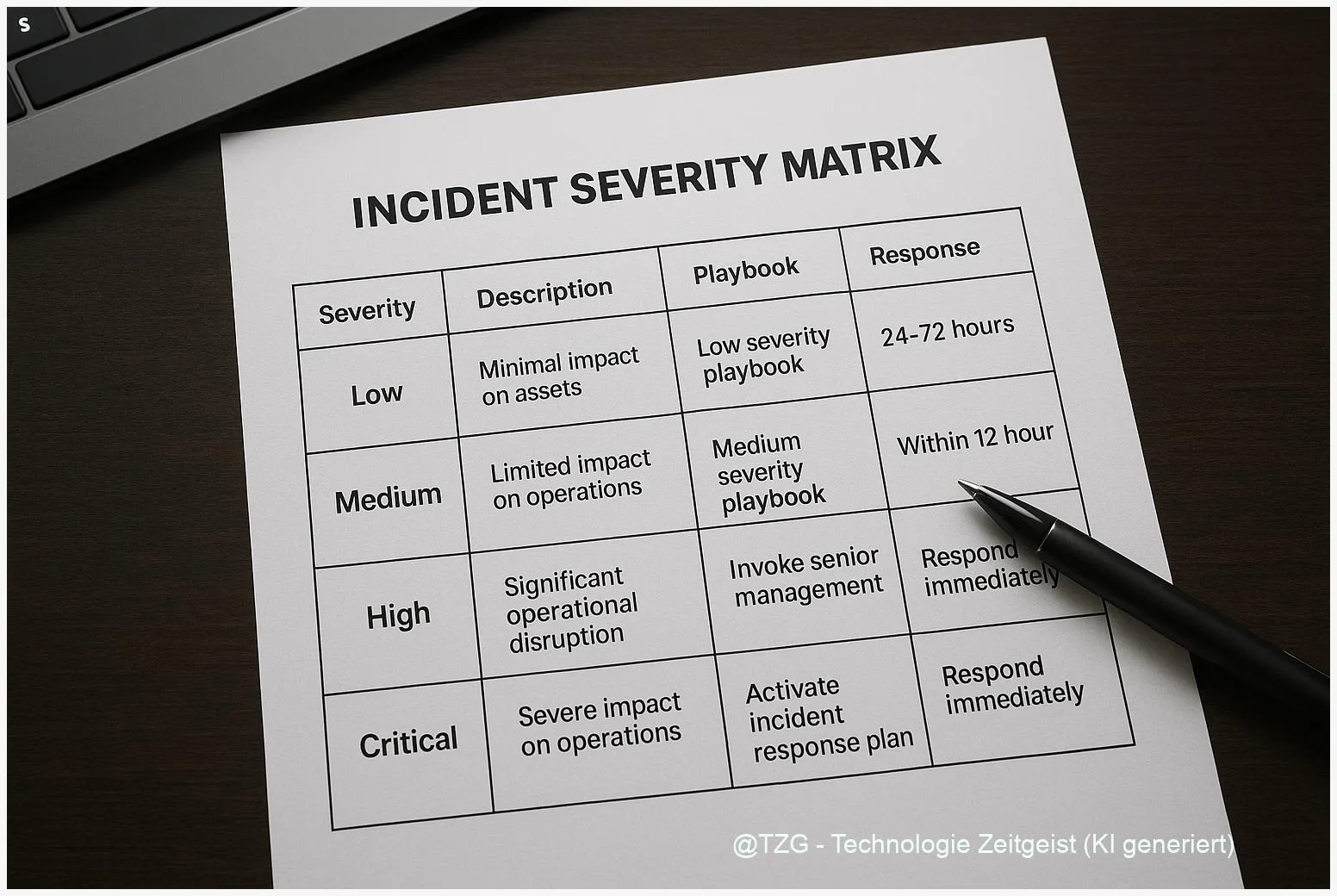
Beispielhaft zeigt die folgende Mini‑Tabelle, wie drei Merkmale in einem ersten MVP abgebildet werden können — zur schnellen Orientierung im SOC‑Shift handhaben Teams so die ersten 10–30 Minuten einer Triage.
| Merkmal | Kurzbeschreibung | Beispiel‑Score |
|---|---|---|
| Technische Schwere | Systemausfall, Model‑Corruption, Exfiltration | 0–100 (z.B. 75) |
| Daten/Modell‑Integrität | Anzeichen für Poisoning, Leakage, Theft | 0–100 (z.B. 60) |
| Business & Regulatorik | Kundendaten betroffen, Meldepflichten, Reputationsrisiko | 0–100 (z.B. 85) |
Das Ziel ist kein perfektes Modell, sondern ein verlässlicher Entscheidungsanker: in den ersten Minuten klare Prioritäten, danach tiefergehende Forensik und TEVV‑Checks.
Designprinzipien einer mehrdimensionalen Severity Matrix
Eine praktikable Matrix beruht auf fünf klaren Prinzipien: Einfachheit, Messbarkeit, Erweiterbarkeit, Kontextsensitivität und Governance‑Verknüpfung. Einfachheit heißt nicht oberflächlich — es geht darum, wenige, robuste Indikatoren zu definieren, die jede Schicht des SOC rasch messen kann. Messbarkeit stellt sicher, dass Scores nicht nach Gefühl entstehen, sondern auf überprüfbaren Signalen basieren.
Konkrete Dimensionen, die sich bewährt haben, sind: technische Schwere, Daten‑/Modellvertrauenswürdigkeit, Output‑Safety (physische oder sicherheitsrelevante Folgen), Business‑ und Compliance‑Impact sowie Forensics‑Aufwand. Jede Dimension erhält definierte Metriken: Prozentualer Datenverlust, ausfallende Antwortraten, Anzahl betroffener Nutzer, nachweisbare Poisoning‑Signaturen oder regulatorische Meldepflichten. Wichtig: Jedes Maß hat Unsicherheitsintervalle, die dokumentiert werden müssen.
Wichtig ist die Gewichtung. Nicht jede Organisation gewichtet Vertraulichkeit gleich — für ein Gesundheitssystem hat Output‑Safety mehr Gewicht als für ein Marketing‑Tool. Deshalb ist die Matrix modular: Kern‑Dimensionen bleiben, ihre Gewichtungen sind parametrisiert und lassen sich pro Use‑Case anpassen. So bleiben Vergleiche möglich, ohne falsche Universalität vorzuschreiben.
Operationaler Tipp: Beginnen Sie mit einer ordinalen Skala (Niedrig / Mittel / Hoch / Kritisch) und übersetzen Sie diese schrittweise in numerische Cutoffs (0–100), wenn historische Daten vorhanden sind. So verbindet die Matrix menschliche Intuition mit datengetriebener Konsistenz.
Die Matrix sollte zudem klar definierte Trigger enthalten: bei Score ≥ X = automatische Isolierung, bei Score zwischen Y und X = erhöhte Überwachung plus Analyst‑Review, bei Score < Y = Dokumentation und Monitoring. Solche Regeln reduzieren kognitive Last während hektischer Schichten und machen Entscheidungen auditierbar.
Schließlich gehört die Matrix in die Governance‑Ebene: Rollen, Reporting‑Pflichten, Meldewege zu Legal und Public Affairs sowie Dokumentation für Post‑mortems müssen verknüpft sein. Nur so entsteht ein lebender Regelkreis, in dem Lessons Learned die Matrix kontinuierlich verbessern.
Implementierung im SOC: Triage‑Workflows und Playbooks
Die technische Umsetzung beginnt bei der Erkennung: automatische Alerts müssen strukturierte Telemetrie liefern — Input‑Hashes, Prompt‑Logs, Modell‑Version, Anomalie‑Metriken. Solche Daten fließen in einen Scoring‑Engine‑Layer, der die Matrix‑Dimensionen kontinuierlich aktualisiert. Wichtiger als perfekte Automatisierung ist die Schnittstelle zur Analystin: das Alert‑Dashboard muss den Score erklären, nicht nur anzeigen.
Ein bewährter Workflow sieht so aus: 1) Automatisierter Vorfilter berechnet einen vorläufigen Score, 2) Analyst prüft Kontextelemente (Logs, Playback, Nutzermeldungen), 3) Incident‑Lead bestätigt Kategorie und leitet Maßnahmen gemäß Playbook ein. Playbooks enthalten feste Schritte: Containment (z. B. Modell‑Rollback oder API‑Key‑Rotation), Forensik‑Sampler (Snapshot‑Traces, Dataset‑Hashes), und Kommunikationsvorlagen für Legal und PR.
Praktisch heißt das: für jeden Severity‑Level existiert ein Katalog kurzfristiger Maßnahmen (0–24 Stunden) und mittelfristiger Schritte (24–72 Stunden). Kurzfristig geht es um Stop‑Gap‑Maßnahmen: Isolieren, Rate‑Limit, Feature‑Toggle. Mittelfristig folgen TEVV‑Prozeduren (Testing, Evaluation, Verification & Validation), Datenforensik und Update‑Prozeduren für Modelle oder Pipelines.
Integrationstipps: verknüpfen Sie das Scoring mit Ticketing (z. B. automatisch ein Incident‑Ticket bei Score ≥ Threshold) und mit Runbooks, die klare Zuständigkeiten benennen. Rollen wie Incident‑Lead, TEVV‑Owner, Data‑Steward, Legal‑Contact sollten im Ticket sichtbar sein. So werden Kommunikationswege kurz und Kontrollpunkte transparent.
Ein letzter Rat: Trainieren Sie das Team regelmäßig mit realistischen Tabletop‑Szenarien. Nur geübte Hände treffen in der Hitze des Vorfalls zügig die richtigen Entscheidungen.
Validierung, Governance und Tabletop‑Übungen
Eine Severity‑Matrix ist nur so gut wie ihre Validierung. Beginnen Sie mit einem MVP, messen Sie Entscheidungen gegen Outcomes und sammeln Sie Post‑mortem‑Daten. Jedes Incident‑Postmortem sollte die Score‑Entscheidung rückkoppeln: Stimmte der Score mit der tatsächlichen Auswirkung überein? Wo lagen Bias oder Messfehler? Solche Analysen generieren die Daten, um Cutoffs zu verfeinern und Unsicherheiten abzuschätzen.
Governance bedeutet klare Verantwortlichkeiten: Wer definiert Gewichtungen? Wer passt Cutoffs an? Wer validiert Instrumente? Legen Sie ein kleines Steering‑Committee aus Security, Data Science, Legal und Business fest, das vierteljährlich die Matrix‑Parameter prüft. Dokumentation ist nicht bureaucracy — sie ist Nachweis bei regulatorischen Anfragen und Lernquelle für das Team.
Tabletop‑Übungen sind der Ort, an dem Theorie zu Praxis wird. Simulieren Sie Vorfälle mit unterschiedlichen Root‑Causes (Poisoning, Leakage, Prompt‑Abuse), spielen Sie den vollen Triage‑Pfad durch und messen Sie Zeit bis Containment, Kommunikationslatenz und Vollständigkeit der Forensik. Achten Sie darauf, externe Stakeholder einzubinden — Legal, Compliance, Kundenbetreuung — damit Schnittstellen erprobt sind.
Abschließend: Validierung ist iterativ. Nutzen Sie Telemetrie aus realen Vorfällen, um Wahrscheinlichkeiten und Fehlermaße zu kalibrieren. Solche Daten helfen, die Matrix robuster zu machen und den SOC von einer reaktiven Einheit zu einer vorausschauenden Organisation zu formen.
Fazit
Eine GenAI incident severity matrix bringt Klarheit in komplexe Entscheidungen: sie verbindet technische Signale mit Business‑ und Safety‑Kontext und schafft auditierbare Eskalationsregeln. Beginnen Sie klein, messen Sie schnell und verfeinern Sie kontinuierlich anhand realer Vorfälle. Binden Sie Governance früh ein, damit Gewichtungen und Cutoffs nachvollziehbar bleiben. Schließlich: Übung macht sicher — Tabletop‑Übungen schließen die Lücke zwischen Regelwerk und praktischer Anwendung.
*Diskutieren Sie Ihre Erfahrungen in den Kommentaren und teilen Sie diesen Leitfaden in Ihren Netzwerken, wenn er Ihnen geholfen hat.*



Schreibe einen Kommentar