Schlagwort: Nvidia
-

Lokales LLM‑Fine‑Tuning: Unsloth & NVIDIA – Feintuning auf dem RTX‑PC
Lokales LLM fine‑tuning macht es möglich, Sprachmodelle direkt auf dem eigenen Rechner anzupassen — ohne Cloud‑Upload sensibler Daten. Dieser Beitrag erklärt praxisnah, wie Unsloth in Kombination

Nvidia wird Modellbauer: Was Nemotron 3 für KI und Europa bedeutet
Nemotron 3 steht für eine neue Modellfamilie von Nvidia, die lange Kontexte, sparsames Rechnen und offene Artefakte kombiniert. Für Europa bedeutet das zugleich Chancen bei
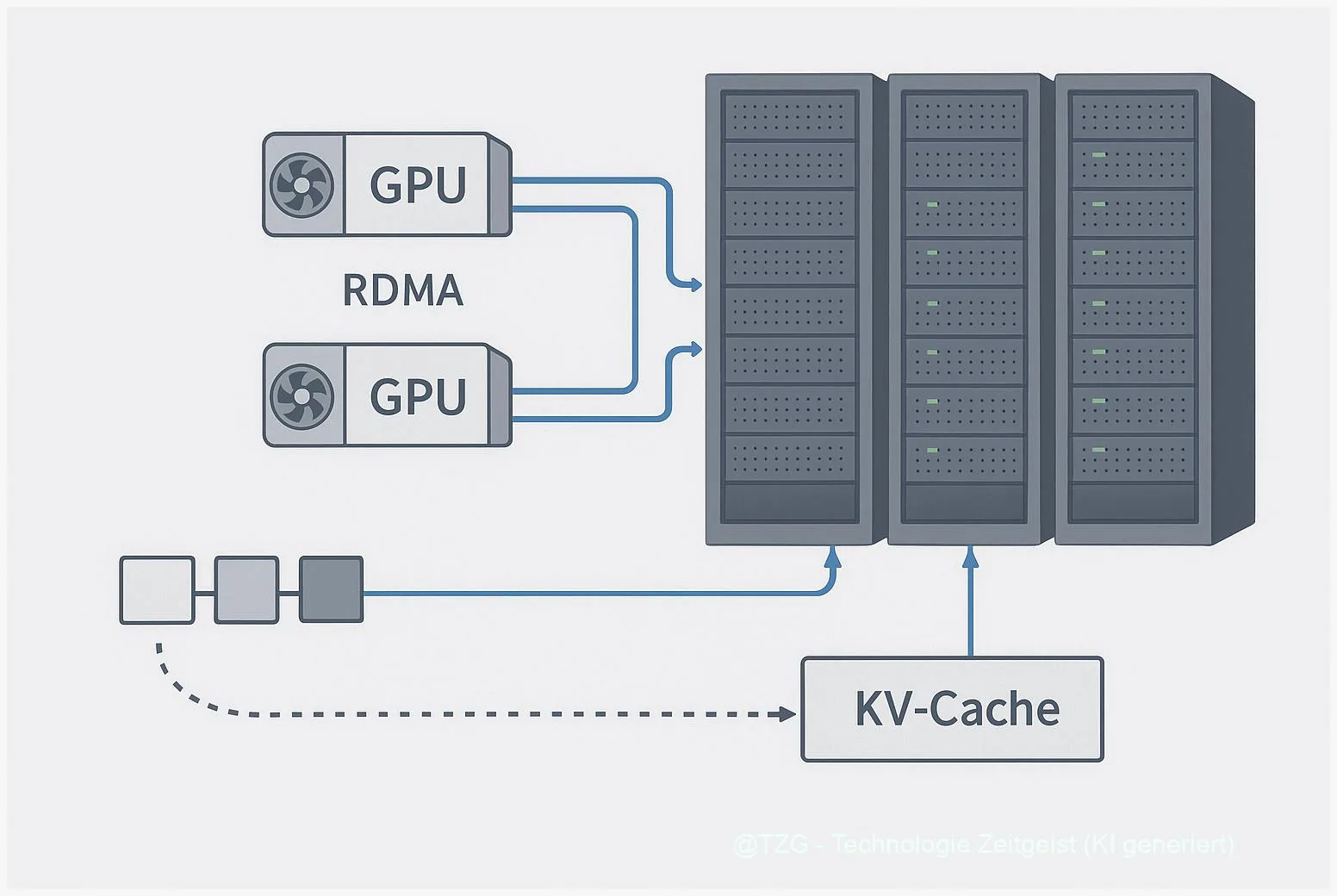
TransferEngine und pplx garden: Trillion‑Parameter‑LLMs auf Ihrem Cluster betreiben
Zuletzt aktualisiert: 2025-11-22 Kurzfassung TransferEngine ist eine portable RDMA‑Abstraktion, die in Projekten wie pplx garden eingesetzt wird, um KV‑Cache‑Streaming, MoE‑Dispatch und punktuelle Weight‑Transfers für Trillion‑Parameter‑Modelle

Wie Nvidias $57B‑Quartal Startups neu über AI‑Compute planen
Zuletzt aktualisiert: 2025-11-20 Kurzfassung Das Nvidia $57B Quartal ist mehr als ein Finanzrekord: es signalisiert, wie stark Rechenkapazität für KI nachgefragt wird und wie knapp

Microsofts Triple‑Play: $9,7 Mrd. IREN‑Deal, VAE‑GPUs, Lambda‑Abkommen
Zuletzt aktualisiert: 7. November 2025 Kurzfassung Microsofts jüngste Ankündigungen — die $9,7 Mrd. Vereinbarung mit IREN, genehmigte Nvidia‑GPU‑Lieferungen in die VAE und das multibillionen‑Abkommen mit Lambda

OpenAI & AWS: $38 Milliarden‑Deal skizziert neue Cloud‑Architektur
Zuletzt aktualisiert: 7. November 2025 Kurzfassung OpenAI hat eine siebenjährige Vereinbarung mit Amazon Web Services geschlossen — ein $38 Milliarden‑Commitment, das sofortigen Zugriff auf hunderte Tausende

NVIDIAs Warnung: Chinas billiger Strom schenkt ihm KI‑Vorteil
Zuletzt aktualisiert: 6. November 2025 Kurzfassung NVIDIA CEO Jensen Huang sorgte Anfang November für Aufruhr, als er laut Financial Times sagte, dass China das KI‑Rennen

2025 Robotics Breakthroughs: Von AMD-Edge-AI bis Toyotas Mobi
Zuletzt aktualisiert: 6. November 2025 Kurzfassung Im November 2025 bündeln sich mehrere Entwicklungen im Feld der AI robotics 2025: Liquid AI und AMD zeigen lokale,

NVIDIA & Telekom: 1 Mrd. € AI‑Gigafactory in München
Zuletzt aktualisiert: 04. November 2025 Kurzfassung Die angekündigte AI‑Gigafactory von NVIDIA und der Deutschen Telekom in München ist ein Projekt mit einem Volumen von rund

Lilly und Nvidia: KI-Supercomputer für schnellere Wirkstoffforschung
Zuletzt aktualisiert: 1. November 2025 Kurzfassung Die Eli Lilly Nvidia Partnerschaft 2025 setzt auf einen firmeneigenen KI‑Supercomputer, der Wirkstoffforschung beschleunigen soll. Dieser Bericht erklärt, was

Nvidia auf 5 Bio.$ — Risiko China-Blackwell
Zuletzt aktualisiert: 30. Oktober 2025 Kurzfassung Die Nvidia-Bewertung: 5 Billionen USD markiert, wie der Markt die Zukunft der KI-Infrastruktur einschätzt. Gleichzeitig warnen Experten davor, dass die

Qualcomm’s AI‑Chip‑Revolution: Wie Neue Prozessoren Nvidia Herausfordern und den Markt Umkrempeln
Zuletzt aktualisiert: 28. Oktober 2025 Kurzfassung Qualcomm AI-Chips 2025 markieren einen strategischen Einsprung in Rechenzentren: Mit Ankündigungen zu AI200/AI250 signalisiert Qualcomm eine ernsthafte Konkurrenz zu

Nvidia investiert in Batterie-Recycling: Redwood Materials beschleunigt den Kreislauf für erneuerbare Energien
Zuletzt aktualisiert: 24. Oktober 2025 Kurzfassung Nvidia setzt mit einer Investition in Redwood Materials auf Batterie-Recycling und schafft so neue Wege für nachhaltige Energiespeicher. Das

GeForce NOW feiert vierjähriges Jubiläum: Spiele jederzeit und überall
In dieser Woche feiert GeForce NOW, die Freiheit des Cloud-Gamings, sein vierjähriges Bestehen mit aufregenden Ankündigungen, die das Spielerherz höher schlagen lassen. Unter den Neuzugängen

Die Zukunft der KI-Forschung: Das National AI Research Resource Pilotprogramm und NVIDIA
Künstliche Intelligenz (KI) ist eine Schlüsseltechnologie für die digitale Transformation, die das Potenzial hat, viele gesellschaftliche Herausforderungen anzugehen und neue Möglichkeiten für Innovationen zu schaffen.