Der Fall rund um manipulierte Downloads eines geleakten KI-Tools verweist auf ein dauerhaftes Problem: Bei KI-Coding-Tools ist nicht nur der Code selbst kritisch, sondern schon der Vertriebsweg. Wer inoffizielle Builds, Mirrors oder Repacks installiert, öffnet einen direkten Zugang zu Quellcode, Tokens, Paketregistern und internen Entwicklungsumgebungen. Der Artikel erklärt, warum solche Leaks zu einem besonders attraktiven Malware-Vektor werden, woran sich vertrauenswürdige Distributionen erkennen lassen und weshalb sich mit Coding-Agenten die Verantwortung in der Software-Lieferkette spürbar verschiebt.
Das Wichtigste in Kürze
- Inoffizielle KI-Tools sind für Angreifer attraktiv, weil sie oft mit hohen Rechten laufen und Zugriff auf sensible Entwicklerzugänge, Repositories und Build-Prozesse haben.
- Vertrauenswürdige Distributionen lassen sich an überprüfbarer Herkunft erkennen: offizieller Kanal, dokumentierte Signaturen oder Prüfsummen, nachvollziehbarer Update-Pfad und möglichst kryptografische Herkunftsnachweise.
- Mit Coding-Agenten wird die Software-Lieferkette breiter: Nicht nur Abhängigkeiten im Produkt zählen, sondern auch die Werkzeuge, die Code erzeugen, ausführen, ändern oder in CI/CD-Pipelines tragen.
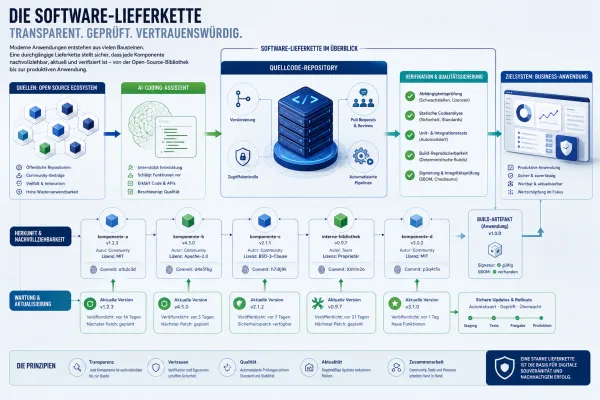
Warum der Download-Kanal plötzlich Teil des Risikos wird
Die Kernfrage lautet nicht, ob ein bestimmtes KI-Tool nützlich ist. Entscheidend ist, wie es ins Unternehmen oder auf Entwicklerrechner gelangt. Gerade bei geleakten, vorab verteilten oder über Community-Mirrors angebotenen KI-Coding-Tools bricht die übliche Vertrauenskette: Der Anbieter kontrolliert den Auslieferungsweg nicht mehr vollständig, Signaturen fehlen oder werden umgangen, und Sicherheits-Teams können Herkunft und Integrität deutlich schwerer prüfen.
Das ist praktisch relevant, weil moderne Coding-Agenten mehr tun als Textvorschläge zu liefern. Sie lesen Dateien, greifen auf Projektordner zu, starten lokale Befehle, installieren Pakete und arbeiten oft mit Cloud-Diensten zusammen. Wird ein solches Werkzeug manipuliert ausgeliefert, betrifft das nicht nur einen einzelnen Rechner. Es kann die gesamte Software-Lieferkette berühren: vom Entwicklergerät über Geheimnisse und Build-Umgebungen bis zur späteren Auslieferung von Software.
Geleakte Tools treffen auf besonders wertvolle Zugänge
Developer-Tools gehören seit Jahren zu den attraktivsten Zielen für Schadsoftware. Der Grund ist einfach: Wer ein Werkzeug kompromittiert, das in der täglichen Entwicklung eingesetzt wird, erhält potenziell Zugriff auf Quellcode, API-Schlüssel, SSH-Zugänge, Paket-Registries, interne Dokumentation und Build-Skripte. Bei KI-Coding-Tools kommt hinzu, dass sie häufig tief in Editor, Terminal und Projektstruktur eingebunden sind. Der Schadcode landet damit nicht irgendwo am Rand, sondern an einem operativen Knotenpunkt.
Lecks und inoffizielle Verteilungen verschärfen dieses Muster. Sie erzeugen Knappheit, Zeitdruck und Neugier. Wer ein eigentlich noch schwer verfügbares oder kostenpflichtiges Tool schnell testen will, akzeptiert leichter Abkürzungen: ein Download aus einem Forum, ein inoffizielles Repository, ein Repack ohne klare Herkunft. Genau dort setzt Malware an. Die Verteidigung scheitert dann nicht an einer exotischen Sicherheitslücke, sondern an einer zerstörten Herkunftskette.
Für Unternehmen ist das heikel, weil die Folgen über den Endpunkt hinausreichen können. Gelangen Angreifer an Zugangsdaten oder Build-Konfigurationen, wird aus einem lokalen Vorfall ein Lieferkettenproblem. NIST ordnet sichere Software-Entwicklung deshalb ausdrücklich nicht nur als Frage des Codes ein, sondern auch als Schutz gegen unbefugte Änderungen und als Kontrolle der eingesetzten Komponenten und Werkzeuge. Der praktische Punkt: Ein kompromittiertes Hilfswerkzeug kann denselben Schaden anrichten wie eine bösartige Abhängigkeit.
Vertrauen beginnt bei Signatur, Herkunft und Update-Pfad
Ob eine Distribution vertrauenswürdig ist, lässt sich selten an einem einzelnen Merkmal festmachen. Ein realistischer Prüfmaßstab besteht aus mehreren Schichten. Erstens braucht es einen offiziellen Auslieferungskanal, der zum Anbieter eindeutig gehört. Zweitens sollten Signaturen, Prüfsummen oder andere kryptografische Nachweise dokumentiert und überprüfbar sein. Drittens ist wichtig, ob der Build-Prozess und die Herkunft eines Artefakts nachvollziehbar gemacht werden, etwa über Attestierungen oder Provenance-Konzepte, wie sie in SLSA beschrieben werden. Viertens muss auch der Update-Mechanismus kontrolliert sein: Ein sauberer Erstdownload nützt wenig, wenn spätere Updates aus unsicheren Quellen kommen.
Für einzelne Entwickler heißt das: Nicht nur auf den Dateinamen schauen, sondern auf Publisher, Herkunft und Verifikationshinweise. Für Unternehmen reicht individuelle Vorsicht aber nicht aus. Nötig sind freigegebene Software-Kataloge, zentrale Paketquellen, Allowlists, Signaturprüfung, Sandboxes für Evaluationen und klar getrennte Testumgebungen ohne produktive Geheimnisse. Wer neue KI-Tools zuerst in einer isolierten Umgebung ausprobiert, reduziert das Risiko erheblich, ohne Innovation komplett auszubremsen.
Hilfreich ist außerdem eine nüchterne Grundregel: Ein Tool ist nicht deshalb vertrauenswürdig, weil es populär ist oder in Entwickler-Communities oft erwähnt wird. Belastbar wird Vertrauen erst, wenn Herkunft, Integrität und Aktualisierung technisch überprüfbar sind. Genau an diesem Punkt reagieren Anbieter meist mit strenger kontrollierten Distributionswegen, Enterprise-Freigaben, signierten Releases und klar dokumentierten Installationspfaden.
Coding-Agenten erweitern die Software-Lieferkette nach vorn
Der klassische Blick auf Software-Lieferketten richtet sich vor allem auf Bibliotheken, Build-Systeme und Abhängigkeiten, die später im Produkt landen. KI-Coding-Tools verschieben den Fokus. Sie sitzen früher im Prozess und beeinflussen, was überhaupt geschrieben, installiert, geändert oder ausgeführt wird. Damit wird die Lieferkette nach vorn erweitert: auf die Werkzeuge, die Entwicklungsentscheidungen vorbereiten oder direkt technische Aktionen auslösen.
Das verändert Verantwortlichkeiten. Anbieter solcher Tools müssen nicht nur ein Modell bereitstellen, sondern auch die sichere Distribution, Update-Integrität, nachvollziehbare Versionierung und administrative Steuerung für Unternehmen liefern. Security- und Plattform-Teams wiederum müssen festlegen, welche Werkzeuge zugelassen sind, welche Rechte sie erhalten und wie Ausgaben geprüft werden. Entwickler bleiben wichtige Nutzer, sind aber nicht mehr die einzige Kontrollinstanz. Wenn ein Agent Dateien anlegt, Befehle startet oder neue Abhängigkeiten vorschlägt, braucht es organisatorische Leitplanken statt bloß individuelles Sicherheitsbewusstsein.
Für Deutschland und Europa ist das besonders relevant, weil in vielen Unternehmen Entwicklungsumgebungen zentral verwaltet werden und Nachvollziehbarkeit in Audits, Compliance-Prüfungen und Beschaffung an Bedeutung gewinnt. Ein KI-Tool ist damit nicht nur Produktivitätssoftware, sondern Teil der Governance-Frage: Wer darf es einführen, auf welchem Weg, mit welchen Rechten und unter welcher technischen Kontrolle?
Offen prüfbar hilft, ersetzt aber keine saubere Auslieferung
Manche Teams reagieren auf diese Risiken, indem sie offene oder selbst betreibbare Alternativen bevorzugen. Das kann sinnvoll sein, weil Quellcode, Build-Schritte und Änderungen prinzipiell besser überprüfbar sind. Offene Werkzeuge erlauben zudem eher reproduzierbare Builds, interne Spiegelserver und eigene Freigabeprozesse. Für sicherheitsbewusste Organisationen ist das oft attraktiver als eine Black-Box-Distribution über inoffizielle Kanäle.
Aber offen bedeutet nicht automatisch sicher. Auch Open-Source-Software kann über kompromittierte Maintainer-Konten, manipulierte Releases, typosquattete Pakete oder unsaubere Mirrors missbraucht werden. Entscheidend bleibt deshalb die Kombination aus überprüfbarer Herkunft, kryptografischer Absicherung und kontrollierter interner Verteilung. Wer nur von einem intransparenten proprietären Leak zu einem zufälligen Community-Build wechselt, hat das Grundproblem nicht gelöst.
Für Unternehmen zählt der Freigabeprozess mehr als der Hype
Der eigentliche Lerneffekt aus manipulierten Leaks ist nicht, dass KI-Coding-Tools grundsätzlich zu gefährlich wären. Das Problem entsteht dort, wo leistungsfähige Entwicklerwerkzeuge ohne belastbare Herkunft in produktionsnahe Umgebungen gelangen. Wer Software-Lieferkette Sicherheit ernst nimmt, sollte KI-Tools wie privilegierte Infrastruktur behandeln: nur über kontrollierte Kanäle, mit überprüfbaren Signaturen und Herkunftsnachweisen, in klar abgegrenzten Teststufen und mit engen Rechten. Dann lässt sich der Nutzen solcher Werkzeuge realistisch erschließen, ohne die Vertrauenskette an ihrem schwächsten Punkt zu öffnen.
Je tiefer ein Tool in Code, Secrets und Builds eingreift, desto strenger sollte sein Freigabeweg sein.