Moderne Software entsteht selten aus einem Stück. KI-Assistenten schreiben Code, Entwickler übernehmen Open-Source-Pakete, Dienste hängen an Bibliotheken, Build-Systemen und Updates. Für Unternehmen und Nutzer zählt deshalb nicht nur, ob eine App funktioniert. Entscheidend ist, ob nachvollziehbar bleibt, wo ihre Bausteine herkommen, wer sie pflegt und wie schnell Sicherheitslücken geschlossen werden.

Warum das Thema jetzt größer wird als Entwickleralltag
Open Source ist die Grundversorgung der digitalen Wirtschaft. Webshops, Banking-Apps, Verwaltungsportale, Bürosoftware und KI-Dienste nutzen Bibliotheken, die nicht jedes Team selbst geschrieben hat. Das ist kein Makel, sondern der Normalzustand moderner Software. Ohne gemeinsame Pakete wären viele Anwendungen langsamer, teurer und schlechter wartbar.
KI verändert diese Lieferkette noch einmal. Ein Coding-Assistent kann in Minuten Funktionen vorschlagen, Abhängigkeiten einbauen oder Code aus bekannten Mustern ableiten. Das spart Zeit. Es verschiebt aber auch die Kontrollfrage: Wer prüft, ob der vorgeschlagene Code wirklich zur eigenen Sicherheitslage passt? Wer sieht, welches Paket neu in ein Produktivsystem wandert? Und wer reagiert, wenn ausgerechnet dieses Paket später eine Schwachstelle enthält?
Für Leser in Deutschland und Europa ist das nicht nur ein Thema für Softwarehäuser. Wenn eine Arztpraxis, ein Handwerksbetrieb, eine Kommune oder ein Onlinehändler digitale Dienste betreibt, hängt deren Verlässlichkeit an solchen unsichtbaren Bausteinen. Schlechte Paketpflege kann Updates verzögern, Daten gefährden oder Supportkosten erhöhen. Gute Herkunftsnachweise machen Software dagegen wartbarer und überprüfbarer.
Was eine Software-Lieferkette überhaupt ist
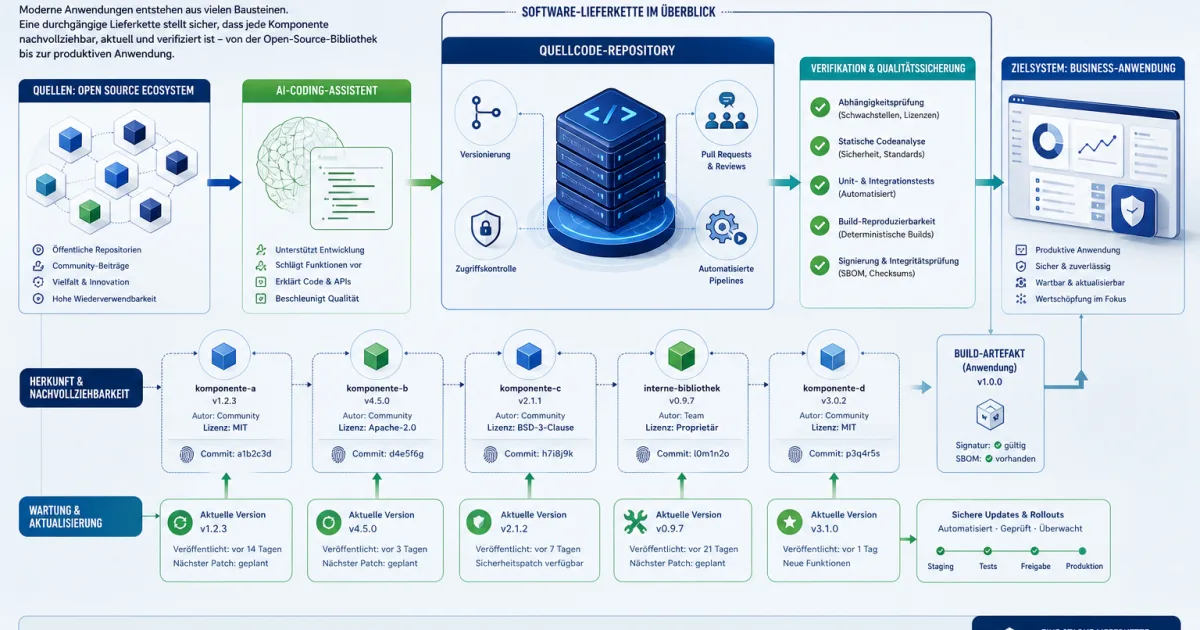
Eine Software-Lieferkette beschreibt den Weg vom Quellcode bis zur laufenden Anwendung. Dazu gehören eigene Entwickler, KI-Werkzeuge, Open-Source-Bibliotheken, Paketmanager, Build-Server, Container, Signaturen, Testsysteme, Deployment-Plattformen und die späteren Updates. In jedem Schritt kann ein Fehler entstehen: ein falsch berechtigtes Token, ein ungeprüftes Paket, ein manipulierbares Build-Skript oder eine Abhängigkeit, die seit Jahren niemand mehr wartet.
Der Begriff klingt industriell, passt aber gut. Auch bei Software entsteht ein Endprodukt aus Vorprodukten. Der Unterschied: Viele Vorprodukte sind digital, frei verfügbar und in Sekunden kopiert. Ein einziges kleines Paket kann deshalb in tausenden Anwendungen landen. Wird es kompromittiert oder plötzlich nicht mehr gepflegt, trifft das nicht nur ein Projekt, sondern eine ganze Kette von Diensten.
OpenSSF, NIST und ENISA behandeln diese Kette deshalb als Sicherheits- und Vertrauensfrage. OpenSSF bündelt Initiativen rund um Open-Source-Sicherheit. NIST betont in seinem KI-Risikomanagement unter anderem Governance, Nachvollziehbarkeit und kontrollierte Prozesse. ENISA ordnet Lieferkettenangriffe und Abhängigkeiten in die europäische Bedrohungslage ein. Für die Praxis folgt daraus: Vertrauen entsteht nicht durch Bauchgefühl, sondern durch sichtbare Kontrollen.
KI-Code ist schnell, aber nicht automatisch freigegeben
Ein KI-Vorschlag ist zunächst ein Arbeitsentwurf. Er kann hilfreich, elegant oder überraschend brauchbar sein. Er kann aber auch eine veraltete Bibliothek empfehlen, eine unsichere Standardeinstellung übernehmen oder Code erzeugen, der zwar im Test läuft, aber Wartung und Rechtekonzept belastet. Hier beginnt der Unterschied zwischen Experiment und Produktivsoftware.
Teams sollten deshalb klar trennen: Darf KI Code nur vorschlagen? Darf sie Abhängigkeiten hinzufügen? Darf sie Tests schreiben? Wer überprüft Lizenz, Sicherheit und Wartbarkeit? Und welche Systeme sind tabu, weil sie Kundendaten, Zahlungsflüsse, Gesundheitsinformationen oder kritische Betriebsprozesse berühren?
Diese Fragen bremsen Innovation nicht aus. Sie verhindern, dass Geschwindigkeit mit Freigabe verwechselt wird. Ein guter Rollout von KI-Coding-Werkzeugen enthält daher Regeln für Repository-Zugriff, Paketinstallation, Review-Pflichten, Protokolle und den Umgang mit sensiblen Daten. Gerade kleinere Unternehmen brauchen dafür keine riesige Governance-Abteilung, aber eine klare Linie: Was in eine produktive Anwendung wandert, muss nachvollziehbar sein.
Woran vertrauenswürdige Pakete erkennbar werden
Das erste Signal ist Herkunft. Ein Paket sollte aus einer nachvollziehbaren Quelle stammen, eine erkennbare Projektseite besitzen und über einen offiziellen Paketmanager oder ein etabliertes Repository eingebunden werden. Kopierte ZIP-Dateien, unbekannte Forks oder einzelne Snippets aus Foren sind schwerer zu prüfen als sauber versionierte Abhängigkeiten.
Das zweite Signal ist Pflege. Wann gab es das letzte Release? Reagieren Maintainer auf Sicherheitsmeldungen? Gibt es mehrere aktive Personen oder hängt alles an einem einzelnen Konto? Ein kleines Paket kann seriös sein, wenn es stabil und überschaubar ist. Problematisch wird es, wenn ein kritischer Baustein seit Jahren unverändert bleibt, offene Sicherheitsmeldungen ignoriert oder plötzlich von neuen, kaum bekannten Maintainer-Konten übernommen wird.
Das dritte Signal ist Transparenz. Eine Software Bill of Materials, kurz SBOM, listet verwendete Komponenten auf. Signierte Releases, reproduzierbare Builds oder Provenienz-Nachweise zeigen zusätzlich, wie ein Artefakt entstanden ist. Nicht jedes Team braucht sofort das volle Programm. Aber wer gar nicht weiß, welche Bibliotheken in seiner Anwendung stecken, kann Schwachstellenmeldungen nur langsam zuordnen.
Was Unternehmen praktisch prüfen sollten
Für produktive Software reicht eine einfache Frage als Startpunkt: Können wir innerhalb weniger Stunden sagen, ob eine gemeldete Schwachstelle uns betrifft? Wenn die Antwort nein lautet, fehlt meist ein sauberes Abhängigkeitsinventar. Dann sind Paketlisten, Lockfiles, Container-Scans und klare Zuständigkeiten wichtiger als das nächste KI-Tool.
Zweitens sollten Teams kritische Abhängigkeiten markieren. Nicht jedes Hilfspaket verdient denselben Aufwand. Ein Framework für Login, Zahlungsabwicklung, Verschlüsselung, Datei-Upload oder API-Zugriffe ist sensibler als ein kleines Formatierungswerkzeug. Für solche Bausteine braucht es strengere Reviews, schnellere Update-Pfade und klare Ausweichpläne.
Drittens gehört KI-Code in den normalen Entwicklungsprozess. Pull Requests, Tests, statische Analyse, Security-Scans und menschliche Reviews bleiben nötig. Der Satz „Das hat die KI geschrieben“ ist keine Freigabe. Er ist ein Hinweis darauf, dass Herkunft und Annahmen besonders sauber geprüft werden sollten.
Viertens sollten Organisationen Abhängigkeiten nicht nur beim Start eines Projekts prüfen. Sicherheitsarbeit ist Betrieb. Updates müssen eingeplant, Breaking Changes bewertet und veraltete Pakete ersetzt werden. Ein Projekt, das heute sauber wirkt, kann in zwölf Monaten riskant sein, wenn niemand mehr auf neue Versionen, CVEs oder Maintainer-Wechsel achtet.
Was Nutzer und Entscheider daraus mitnehmen können
Nutzer sehen die Software-Lieferkette selten direkt. Trotzdem gibt es Indizien. Seriöse Anbieter kommunizieren Sicherheitsupdates, pflegen Changelogs, reagieren auf Schwachstellen und erklären, welche Daten verarbeitet werden. Bei Unternehmenssoftware lohnt die Nachfrage nach Update-Prozess, Sicherheitskontrollen, Hosting, Supportdauer und Umgang mit Open-Source-Komponenten.
Entscheider sollten außerdem zwischen Feature-Tempo und Betriebsreife unterscheiden. Ein Anbieter, der jede Woche KI-Funktionen ankündigt, aber keine belastbaren Aussagen zu Sicherheit, Abhängigkeiten und Datenzugriff macht, liefert ein unvollständiges Bild. Gute Software ist nicht die, die am schnellsten neue Bausteine stapelt. Gute Software bleibt erklärbar, updatefähig und überprüfbar.
Für öffentliche Stellen, regulierte Branchen und kritische Geschäftsprozesse wird diese Einordnung besonders wichtig. Dort können Paketquellen, Signaturen, Audit-Trails und Lieferantenauskünfte über Ausschreibungen, Freigaben und Haftungsfragen entscheiden. Software-Lieferketten sind damit kein Nebenthema der IT-Abteilung, sondern Teil von Beschaffung, Risikomanagement und digitaler Souveränität.
Der kurze Entscheidungscheck
Vor einem neuen Paket oder KI-Code-Vorschlag hilft eine knappe Prüfung. Erstens: Welche Funktion erfüllt der Baustein, und ist er wirklich nötig? Zweitens: Woher kommt er, wer pflegt ihn, und wann wurde er zuletzt aktualisiert? Drittens: Welche Berechtigungen, Netzwerkzugriffe oder Datenflüsse entstehen dadurch? Viertens: Wie schnell lässt sich der Baustein ersetzen oder patchen, wenn etwas schiefgeht?
Fünftens: Ist der Einsatz ein Experiment, ein internes Werkzeug oder Teil eines produktiven Dienstes? Je näher ein Baustein an Kundendaten, Zahlungen, Identitäten oder Betriebsprozessen liegt, desto höher muss die Hürde sein. Sechstens: Gibt es einen sichtbaren Nachweis, welche Version eingesetzt wird? Ohne diese Spur wird jede spätere Schwachstellenmeldung zur Suchaktion.
Der wichtigste Punkt bleibt nüchtern: KI und Open Source sind starke Beschleuniger. Sicher werden sie erst, wenn Herkunft, Wartung und Freigabe mitwachsen. Wer diese Lieferkette kennt, kann schneller entwickeln, ohne die Kontrolle über die eigene Software zu verlieren.
Quellen und weiterführende Informationen
Wichtige Ausgangspunkte für die Einordnung waren diese offiziellen und institutionellen Quellen:
Passende TechZeitGeist-Kontexte: Cyberlage Deutschland: digitale Resilienz im Alltag · KI-Regeln für Team-Chatbots bei der Arbeit · KI-Erweiterungen im Browser: Zugriffe prüfen
Hinweis: Für diesen Artikel wurden KI-gestützte Recherche- und Editierwerkzeuge verwendet. Der Inhalt wurde menschlich redaktionell geprüft. Stand: 04.06.2026.