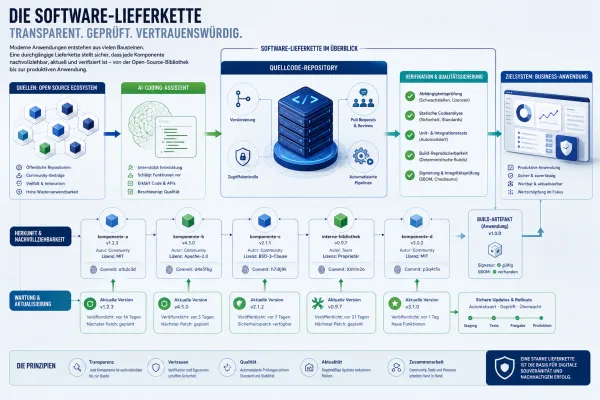
Ein rund 13 Stunden dauernder AWS Ausfall im Dezember 2025 hat gezeigt, wie eng KI-gestützte Automatisierung und operative Risiken zusammenhängen. Betroffen war laut Reuters ein Kostenmanagement-Dienst in einer Region in Festlandchina. Während AWS von einer Fehlkonfiguration mit zu weitreichenden Berechtigungen spricht, berichten Medien über die Rolle eines internen KI-Coding-Tools. Für dich als Cloud-Kunde zählt vor allem: Wie senkst du Ausfallkosten, reduzierst Sicherheitsrisiken und handelst in den ersten 60 Minuten strukturiert?
Einleitung
Wenn deine Anwendung plötzlich keine Nutzungs- oder Kostendaten mehr anzeigt, wirkt das im ersten Moment harmlos. Doch nach ein paar Stunden wird klar: Ohne diese Daten fehlen Entscheidungsgrundlagen, Abrechnungen verzögern sich, interne Reports bleiben leer. Genau das ist beim gemeldeten AWS Ausfall im Dezember 2025 passiert.
Nach Berichten von Reuters und der Financial Times war ein Kostenmanagement-Dienst von AWS rund 13 Stunden lang gestört. Betroffen war eine einzelne Region in Festlandchina. AWS sprach von einer Fehlkonfiguration mit zu weitreichenden Berechtigungen. Medienberichte verweisen zusätzlich auf ein internes KI-Tool mit dem Namen “Kiro”, das Änderungen ausgeführt haben soll.
Unabhängig davon, welche Ursache am Ende im Detail zutraf, zeigt der Vorfall ein Muster. Wenn Automatisierung und KI mit weitreichenden Rechten arbeiten, steigt der mögliche Schaden bei Fehlern. Für dich als Cloud-Kunde geht es deshalb nicht um Schuldfragen, sondern um Vorsorge. Was kannst du konkret tun, um Ausfallkosten zu begrenzen und Risiken durch KI-Automatisierung zu kontrollieren?
Was über den AWS-Ausfall bekannt ist
Laut Reuters dauerte die Störung rund 13 Stunden und betraf eine Kostenmanagement-Funktion von AWS. Es handelte sich nicht um einen globalen Ausfall von Kernservices wie Recheninstanzen oder Objektspeicher, sondern um einen spezifischen Dienst in einer einzelnen Region.
AWS bezeichnete den Vorfall als “extremely limited event” und führte ihn auf eine Fehlkonfiguration zurück. Ein Ingenieur habe weiterreichende Berechtigungen besessen als vorgesehen. Das Unternehmen betonte, dass ein solcher Fehler grundsätzlich auch ohne KI-Tool möglich gewesen wäre.
Laut Reuters erklärte AWS, die Störung sei auf Benutzerfehler und eine falsch konfigurierte Rolle zurückzuführen gewesen.
Die Financial Times berichtete unter Berufung auf interne Quellen, ein agentisches KI-Coding-Tool habe Änderungen ausgeführt und eine Umgebung gelöscht und neu erstellt. Eine öffentlich zugängliche, technische Detailanalyse mit konkreten API-Aufrufen oder Konfigurationsausschnitten liegt nicht vor.
Wichtig für dich: Selbst wenn nur ein einzelner Dienst in einer Region betroffen war, können solche Ereignisse betriebliche Prozesse empfindlich treffen. Gerade Kosten- und Nutzungsdaten sind oft Grundlage für Budgetplanung, Kundenabrechnung oder interne Steuerung.
Wie KI-Automatisierung Risiken verstärkt
Automatisierung ist in Cloud-Umgebungen Standard. Infrastruktur wird per Code verwaltet, Deployments laufen automatisch, Änderungen werden in Pipelines geprüft und ausgerollt. Kommt ein KI-Tool hinzu, das Code generiert oder Änderungen vorschlägt, steigt die Geschwindigkeit weiter.
Das Problem entsteht, wenn Geschwindigkeit auf zu breite Berechtigungen trifft. Hat ein Tool Schreib- oder Löschrechte in Produktionsumgebungen, reicht eine falsche Annahme oder eine missverstandene Anweisung, um weitreichende Änderungen auszulösen. Selbst wenn ein Mensch die Aktion formal freigibt, kann Routine dazu führen, dass Prüfungen oberflächlich bleiben.
Typische Fehlerketten sehen so aus: Eine Konfigurationsänderung wird automatisiert ausgerollt, Monitoring schlägt nicht sofort an, weil Schwellenwerte unpassend gesetzt sind, und Backups wurden zwar erstellt, aber nie realistisch getestet. Am Ende steht eine Wiederherstellung unter Zeitdruck.
Die AWS Well-Architected-Leitlinien betonen seit Jahren Prinzipien wie “Least Privilege” und klare Change-Prozesse. Ein KI-Tool ändert daran nichts. Im Gegenteil: Je autonomer ein System agiert, desto strikter müssen Berechtigungen, Genehmigungen und Protokollierung sein.
Kosten, SLA und Kommunikation im Ernstfall
Ein 13-stündiger Ausfall eines einzelnen Dienstes bedeutet nicht automatisch massive Vertragsstrafen. Doch er kann indirekte Kosten verursachen. Fehlende Abrechnungsdaten verzögern Rechnungen. Interne Teams investieren zusätzliche Stunden in Analyse und Kommunikation. Führungskräfte wollen wissen, was passiert ist.
Ob dir Service-Credits zustehen, hängt von den jeweiligen Service Level Agreements ab. Diese sind klar definiert und an messbare Verfügbarkeitswerte gebunden. Für den konkret berichteten Vorfall wurden öffentlich keine spezifischen Service-Credits genannt. Das heißt für dich: Du musst selbst prüfen, ob Schwellenwerte in deiner Region und für deinen Service unterschritten wurden.
Ebenso wichtig ist die Incident-Kommunikation. Wer informiert Kunden, Partner oder interne Stakeholder? Gibt es eine vorbereitete Vorlage, die sachlich erklärt, was bekannt ist und was noch geprüft wird? Gerade bei Vorfällen mit KI-Bezug reagieren viele sensibel. Eine nüchterne, faktenbasierte Kommunikation verhindert unnötige Spekulationen.
Halte außerdem fest, welche internen Prozesse während des Ausfalls blockiert waren. Diese Dokumentation hilft dir später, gezielt in Redundanz oder Prozessanpassungen zu investieren.
Checkliste für mehr Resilienz im Alltag
Resilienz beginnt vor dem Ausfall. Eine Multi-Region-Strategie stellt sicher, dass kritische Workloads in mindestens zwei geografisch getrennten Regionen laufen. Fällt eine Region oder ein Dienst aus, kann ein Failover greifen. Entscheidend ist, dass dieser Mechanismus regelmäßig getestet wird.
Backups allein reichen nicht. Du solltest Wiederherstellungen unter realistischen Bedingungen üben. Nur so erkennst du, ob Abhängigkeiten, Berechtigungen oder Netzwerkkonfigurationen den Restore verzögern.
Für KI- und Automatisierungstools gelten zusätzliche Regeln. Gib ihnen nur die minimal notwendigen Rechte. Kritische Aktionen wie das Löschen von Produktionsressourcen sollten technisch durch explizite Verbote abgesichert sein. Ergänze das durch verpflichtende Freigaben mit mindestens zwei Personen für Änderungen an produktiven Umgebungen.
In den ersten 60 Minuten eines Ausfalls zählt Struktur. Prüfe den offiziellen Status deines Cloud-Anbieters. Aktiviere dein internes Incident-Response-Team. Sichere Logs und Zugriffsprotokolle, bevor weitere Änderungen erfolgen. Definiere eine Person, die Kommunikation bündelt, damit Informationen konsistent bleiben.
Diese Schritte sind kein theoretisches Sicherheitskonzept. Sie sind handfeste Werkzeuge, um das Risiko durch KI-Automatisierung zu begrenzen und im Ernstfall handlungsfähig zu bleiben.
Fazit
Der gemeldete AWS Ausfall mit einer Dauer von rund 13 Stunden zeigt, wie schnell aus einer Fehlkonfiguration ein längerer Dienstunterbruch werden kann. Ob ein KI-Tool direkt beteiligt war oder nicht, ändert wenig an der zentralen Lehre. Automatisierung braucht klare Grenzen, saubere Berechtigungen und nachvollziehbare Freigaben.
Für dich heißt das: Prüfe deine IAM-Rollen, teste deine Backups realistisch und simuliere Ausfälle, bevor sie real auftreten. Kosten entstehen oft nicht nur durch die Downtime selbst, sondern durch fehlende Vorbereitung. Wer Resilienz als kontinuierliche Aufgabe versteht, reduziert Stress, Ausfallkosten und Reputationsrisiken deutlich.
Teile diesen Leitfaden mit deinem Team und überprüft gemeinsam eure Cloud-Checkliste, bevor der nächste Ausfall euch dazu zwingt.