Schlagwort: LLM
-

RAG offline betreiben: So funktioniert ein lokales Retrieval‑System sicher
RAG offline betreiben bietet die Möglichkeit, große Textsammlungen lokal zur Beantwortung von Anfragen zu nutzen, ohne Referenzdaten an externe Anbieter zu schicken. Dieser Beitrag erklärt,

Generative Modelle einfach erklärt: Sampling, Mapping und ein klarer Vergleich
Generative Modelle beschreiben, wie Computer neue Daten erzeugen — von Bildern bis Texten. Dieses Stück zeigt, wie unterschiedliche Prinzipien wie Sampling und Mapping bei Variational

Neues Audio‑LLM Step‑Audio‑R1 nutzt Test‑Time Compute Scaling
Zuletzt aktualisiert: 30. November 2025 Berlin, 30. November 2025 Insights Step‑Audio‑R1 ist ein neues Audio‑LLM, das Modality‑Grounded Reasoning Distillation (MGRD) mit Test‑Time Compute Scaling kombiniert.

Audio LLM: Wie Computer Hören, Verstehen und Antworten
Audio LLM sind Modelle, die Ton und Sprache direkt in große Sprachmodelle einbinden, um Fragen zu hören, Inhalte zu übersetzen oder Audio in Text und

KI und Energiebedarf großer Sprachmodelle
Große Sprachmodelle brauchen Rechenleistung — und damit Strom. Das Thema “KI und Energiebedarf großer Sprachmodelle” betrifft sowohl die Betreiber von Rechenzentren als auch Menschen, die

Prompt Engineering: So schreiben Sie klare Prompts für bessere KI‑Antworten
Prompt Engineering ist die Kunst, Eingaben an große Sprachmodelle so zu formulieren, dass die Antworten präzise, nützlich und verlässlich sind. Dieses Stück erklärt nachvollziehbar, warum

Tinygrad-Transformer verstehen: Komponenten eines Mini‑GPT Schritt für Schritt
Tinygrad Transformer verstehen Schritt für Schritt: Dieses Stück zeigt, wie die Kernelemente eines Transformer‑Modells in tinygrad zusammenwirken und welche Teile wirklich wichtig sind, wenn man
Neuro‑symbolische KI: Wie Lernen und Logik zusammenspielen
Neuro‑symbolische KI kombiniert neuronale Netze mit symbolischer Logik, um Lernen und strukturiertes Denken zu verbinden. Für viele Aufgaben – von visueller Erkennung bis zur Entscheidungsfindung

Agent0 einfach erklärt: Wie selbstlernende Agenten ohne Daten arbeiten
Agent0 ist ein Ansatz für selbstverbessernde KI-Agenten, die praktisch ohne externe Trainingsdaten auskommen. In einfachen Worten: Ein Curriculum‑Agent erzeugt Aufgaben, ein Executor‑Agent löst sie mit

Fara-7B: Ein 7 Milliarden‑Parameter‑Agent für Computer‑Aufgaben
Fara-7B ist ein 7 Milliarden Parameter großes Modell, das gezielt dafür trainiert wurde, grafische Benutzeroberflächen per Bildschirminput zu verstehen und Aktionen wie Klicken, Tippen oder Scrollen auszugeben.
Cell2Sentence: Wie KI einzelne Zellen in verständlichen Text übersetzt
Cell2Sentence macht aus Einzelzell‑Genexpressionsdaten kurze, geordnete Text‑„Sätze“, die Maschinen lesen und verarbeiten können. Dieses Verfahren hilft, komplexe scRNA‑seq‑Profile leichter zu vergleichen, automatisch zu beschreiben und

RAG lokal mit Ollama und FAISS: So läuft eine Offline‑RAG
Zuletzt aktualisiert: 22. November 2025 Berlin, 22. November 2025 Insights RAG lokal mit Ollama und FAISS macht Retrieval‑Augmented Generation vollständig offline möglich. Lokale Embeddings (Ollama)

Künstliche Intelligenz: Grundlagen und Alltagsnutzen
Insight Künstliche Intelligenz verändert unseren Alltag spürbar. Dieser Artikel erklärt die Grundlagen, zeigt praktische Anwendungen und beleuchtet Chancen sowie Risiken. Lesen Sie, wie KI-Systeme lernen,
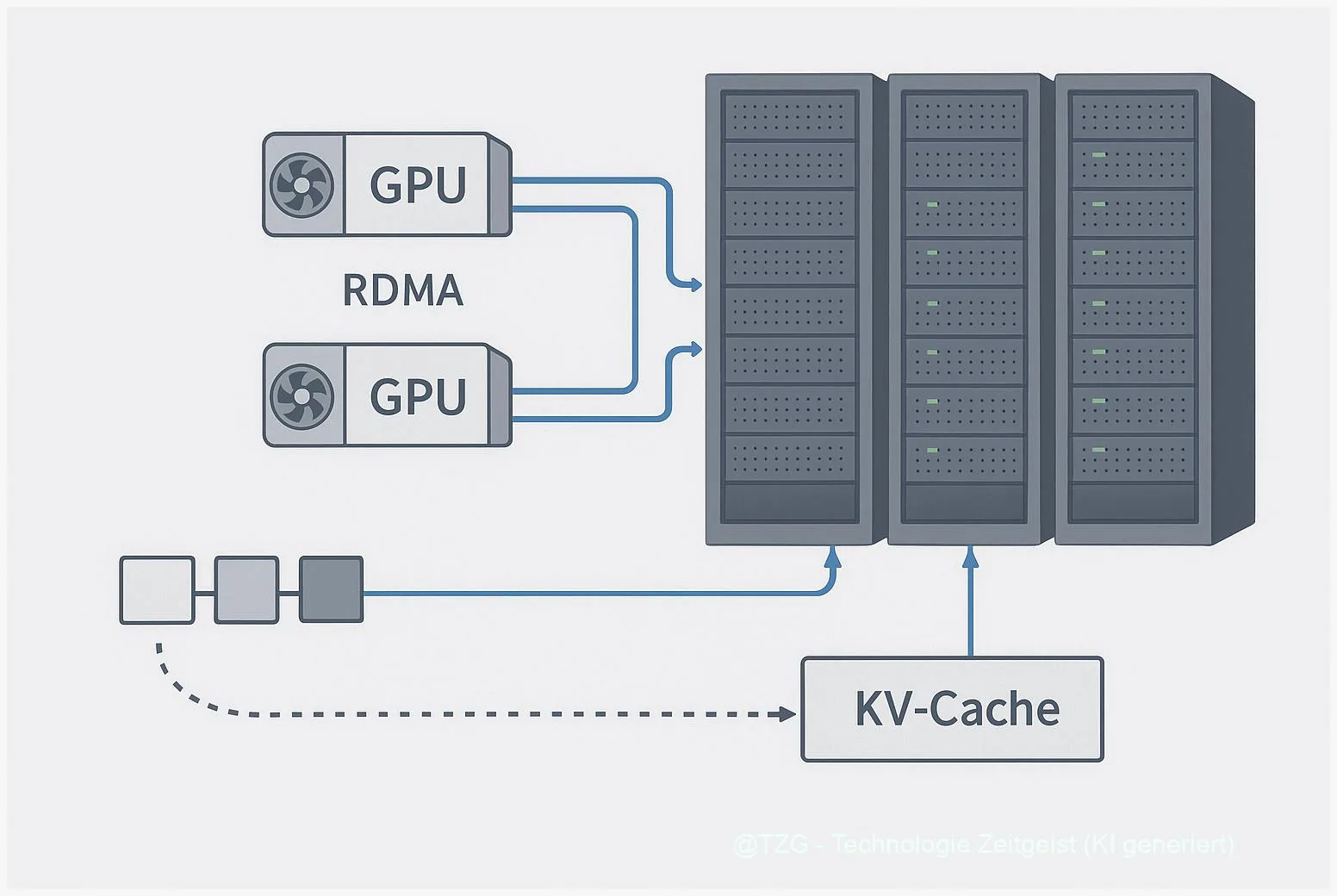
TransferEngine und pplx garden: Trillion‑Parameter‑LLMs auf Ihrem Cluster betreiben
Zuletzt aktualisiert: 2025-11-22 Kurzfassung TransferEngine ist eine portable RDMA‑Abstraktion, die in Projekten wie pplx garden eingesetzt wird, um KV‑Cache‑Streaming, MoE‑Dispatch und punktuelle Weight‑Transfers für Trillion‑Parameter‑Modelle

Transparente lokale LLM‑Pipelines mit Opik und Colocated Models
Zuletzt aktualisiert: 2025-11-22 Kurzfassung Opik local LLM pipeline ist heute ein pragmatischer Weg, um LLM‑Anwendungen lokal beobachtbar und reproduzierbar zu betreiben. Dieser Artikel zeigt, wie