Schlagwort: LLM
-

5 KI‑Architekturen, die du verstehen solltest
Fünf grundlegende KI‑Architekturen prägen heute Forschung und Produkte: dichte Transformer‑Modelle (LLM), Vision‑Language‑Modelle, Mixture‑of‑Experts, große Aktionsmodelle und kompakte Modelle für Geräte. Wer sich mit KI beschäftigt,

KI‑Grundlagen verständlich: Wie Sprachmodelle arbeiten und was zählt
KI Grundlagen sind der Schlüssel, um zu verstehen, warum Sprachassistenten so plausibel wirken und welche Folgen das hat. In diesem Text erfahren Sie in kompakten

SLMs auf dem Smartphone: Wie kleine Sprachmodelle lokal funktionieren
Kleine, effiziente Sprachmodelle machen mehr möglich, ohne dass Texte oder Anfragen ein externes Rechenzentrum erreichen müssen. Small Language Models SLMs für Smartphones sparen Speicher und
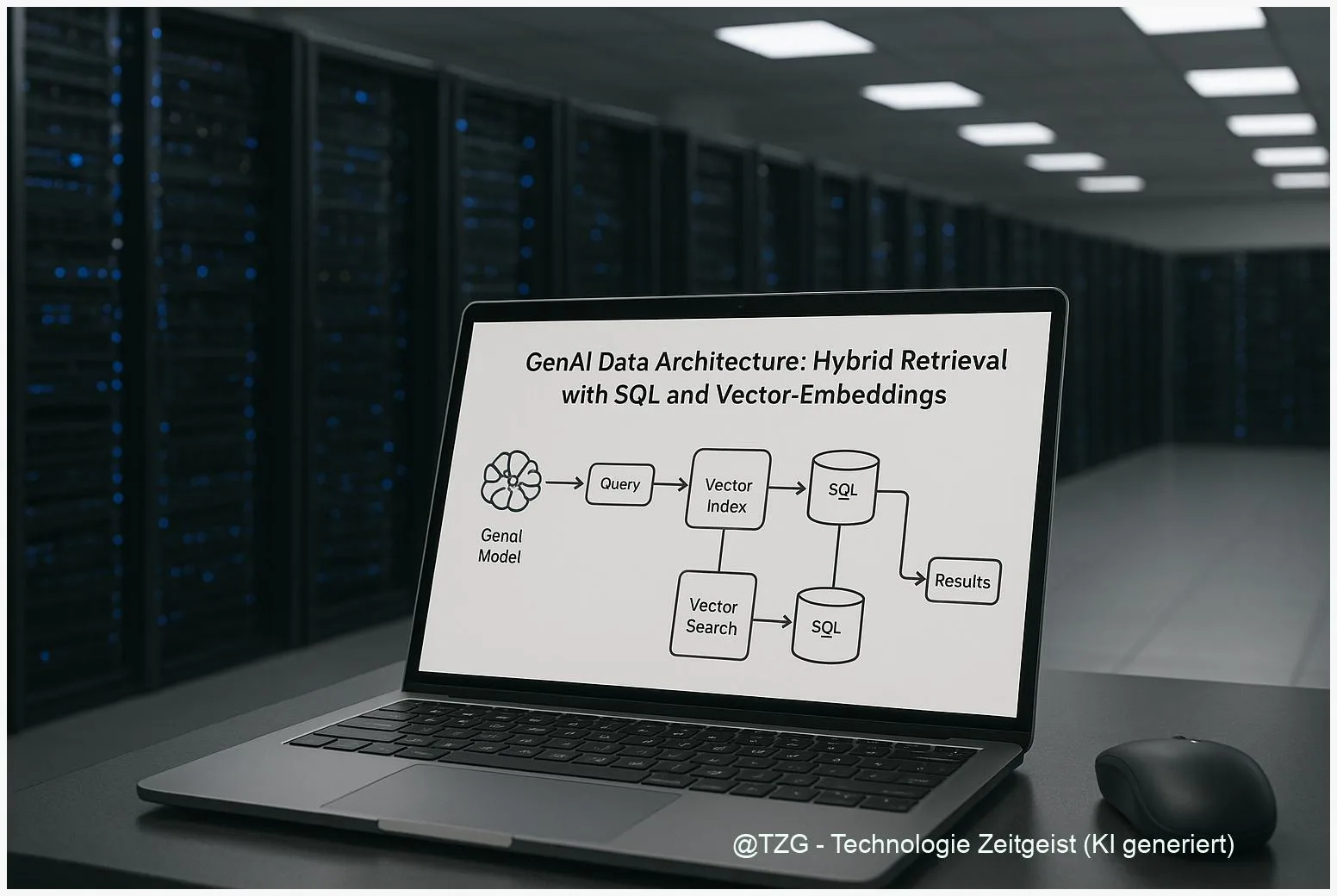
GenAI Datenarchitektur: Hybrid Retrieval mit SQL und Vector-Embeddings
Die GenAI Datenarchitektur entscheidet, wie Unternehmen Wissen verlässlich für generative Modelle abrufen. Hybrid Retrieval verbindet dichte Vector‑Embeddings mit klassischer SQL‑ oder Keyword‑Suche und reduziert so

OpenAI veröffentlicht GPT‑5.2: Neues Modell für professionelle Aufgaben
Zuletzt aktualisiert: 12. December 2025 Berlin, 12. December 2025 Insights OpenAI hat mit GPT‑5.2 ein neues Modell für professionelle Aufgaben vorgestellt. GPT‑5.2 bietet laut OpenAI

Wie man Daten‑Drift erkennt: Datenqualität für KI im Betrieb
Datenqualität für KI entscheidet im Betrieb oft darüber, ob Vorhersagen verlässlich bleiben. Dieses Kurzportrait erklärt, warum Daten‑ und Konzept‑Drift auftreten, wie gängige Erkennungsverfahren funktionieren und
Mistral: Devstral 2 und Vibe CLI — Kurzüberblick für Entwickler
Zuletzt aktualisiert: 10. December 2025 Berlin, 10. December 2025 Insights Mistral Devstral 2 ist ein großes Coding‑Modell mit langem Kontextfenster; parallel erschien die Open‑Source‑CLI Mistral

RAG-Dokumentkompression: Effizient große Textsammlungen nutzen
RAG Dokumentkompression hilft, riesige Textbestände so zu verkleinern, dass semantische Suche und generative Modelle weiterhin korrekte Antworten liefern. In diesem Text steht, wie Produktquantisierung, semantische

Wie ein Geständnis‑System KI ehrlicher macht
Ein Geständnis-System für KI soll Modelle veranlassen, getrennte Ehrlichkeits‑Berichte abzugeben, wenn sie Anweisungen nicht vollständig befolgen oder unsicher sind. In ersten Proof‑of‑Concept‑Tests berichteten Hersteller, dass

ReMem Framework: Wie LLM‑Agenten aus Erfahrungen lernen
Das ReMem Framework verbessert, wie Sprachmodelle vergangene Interaktionen speichern und wiederverwenden, sodass Agenten komplexere Aufgaben mit wiederkehrenden Informationen besser lösen. Im Abstract erläutert dieses Stück,

Mistral 3 Inferenz: Was steckt hinter der 10×‑Aussage?
Anbieter und Medien nennen für Mistral 3 in Verbindung mit NVIDIAs GB200 NVL72 ungewöhnlich hohe Beschleunigungen — oft als “10×” formuliert. Diese Zahl fällt in

Prompt-Injection schützen: Schutzmaßnahmen für KI‑Apps
Prompt-Injection schutzmaßnahmen sind zentral, wenn Anwendungen auf großen Sprachmodellen arbeiten. Dieser Text beschreibt, was Prompt‑Injection bedeutet, warum externe Inhalte schnell zu unbeabsichtigten Anweisungen werden können

Skalierbare AI‑Dokumentenpipeline: Architektur und praktische Anleitung
Eine skalierbare AI Dokumentenpipeline hilft, große Mengen an Texten zuverlässig zu durchsuchen, relevante Passagen zu finden und darauf basierend präzise Antworten zu erzeugen. Sie verbindet

Gemini 3 in Minuten geknackt: Was der Jailbreak für Nutzer bedeutet
Zuletzt aktualisiert: 01. December 2025 Berlin, 01. December 2025 Insights Forscher konnten einen Gemini 3 jailbreak binnen Minuten durchführen und so Sicherheitsregeln umgehen. Der Vorfall

KI‑Nutzungsgrenzen: Warum Anbieter Limits setzen — und was hilft
KI Nutzungsgrenzen sind heute für viele Nutzerinnen und Nutzer spürbar: Plattformen setzen tägliche oder stündliche Limits, unterschiedliche Abos haben verschiedene Kontingente, und API‑Zugänge sind oft