Neuigkeiten
Neuigkeiten
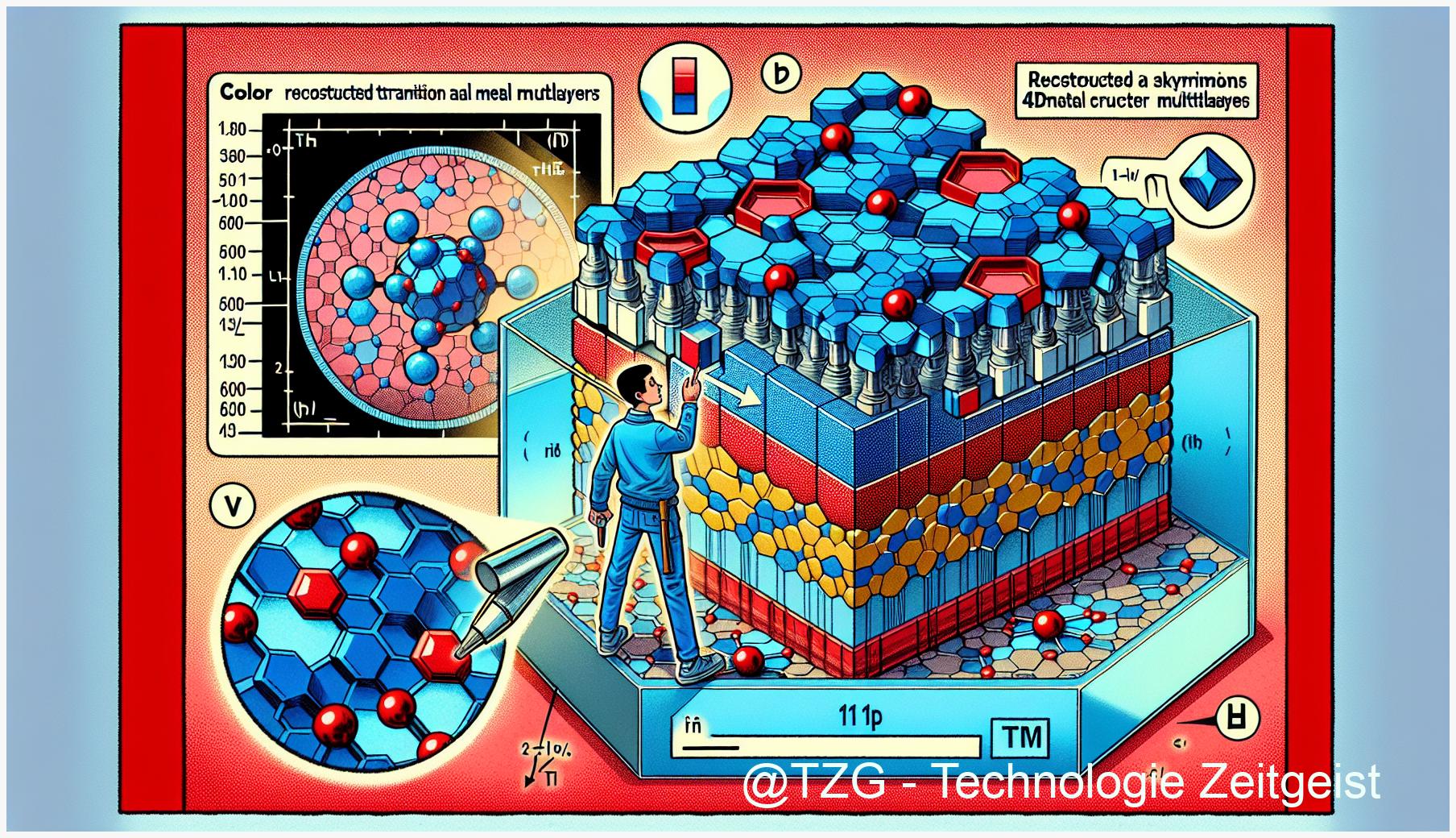
Ignorierst du FlashAttention‑3, rechnet deine KI jetzt doppelt so langsam – 1,2 PFLOPs auf H100 erklärt
Der neue Preprint FlashAttention-3 sorgt für einen Quantensprung bei der Effizienz von Transformer-Attention: Drei clevere Optimierungen…
24. Apr. 2025