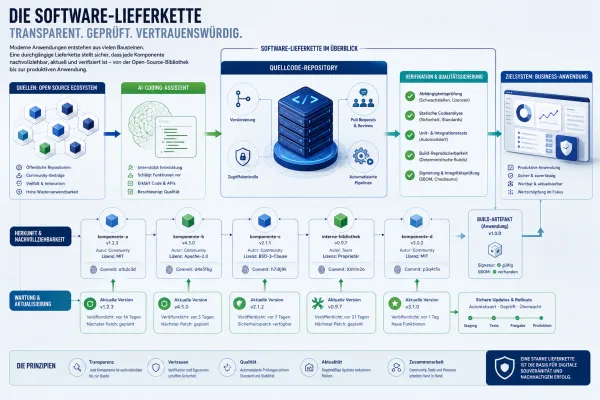
SLSA ist ein Sicherheitsrahmen für Software-Lieferketten. Er beschreibt, wie Quellcode, Build-Prozesse, Artefakte und Nachweise so abgesichert werden, dass Manipulationen deutlich schwerer und später prüfbar werden. Wichtig ist dabei nicht ein einzelnes Tool, sondern die Kombination aus reproduzierbaren Abläufen, Herkunftsnachweisen und klaren Vertrauensgrenzen.

Warum ist das Thema relevant?
Moderne Software entsteht selten vollständig in einem Unternehmen. Entwickler nutzen Open-Source-Bibliotheken, Container-Images, CI/CD-Plattformen, Paketregistries, Build-Runner, Cloud-Dienste und Deployment-Automation. Jede Station kann nützlich sein, ist aber zugleich ein möglicher Angriffspunkt. Wer nur den fertigen Code betrachtet, sieht deshalb nur einen Teil des Risikos.
Angriffe auf Software-Lieferketten nutzen genau diese Lücken. Ein kompromittiertes Build-Skript, ein manipuliertes Paket, ein falsch berechtigter CI-Runner oder ein gestohlener Signing-Key kann reichen, um schädlichen Code in eigentlich vertrauenswürdige Software zu bringen. SLSA setzt hier an: Es macht die Entstehung eines Artefakts nachvollziehbarer und zwingt Teams, kritische Übergänge kontrolliert zu gestalten.
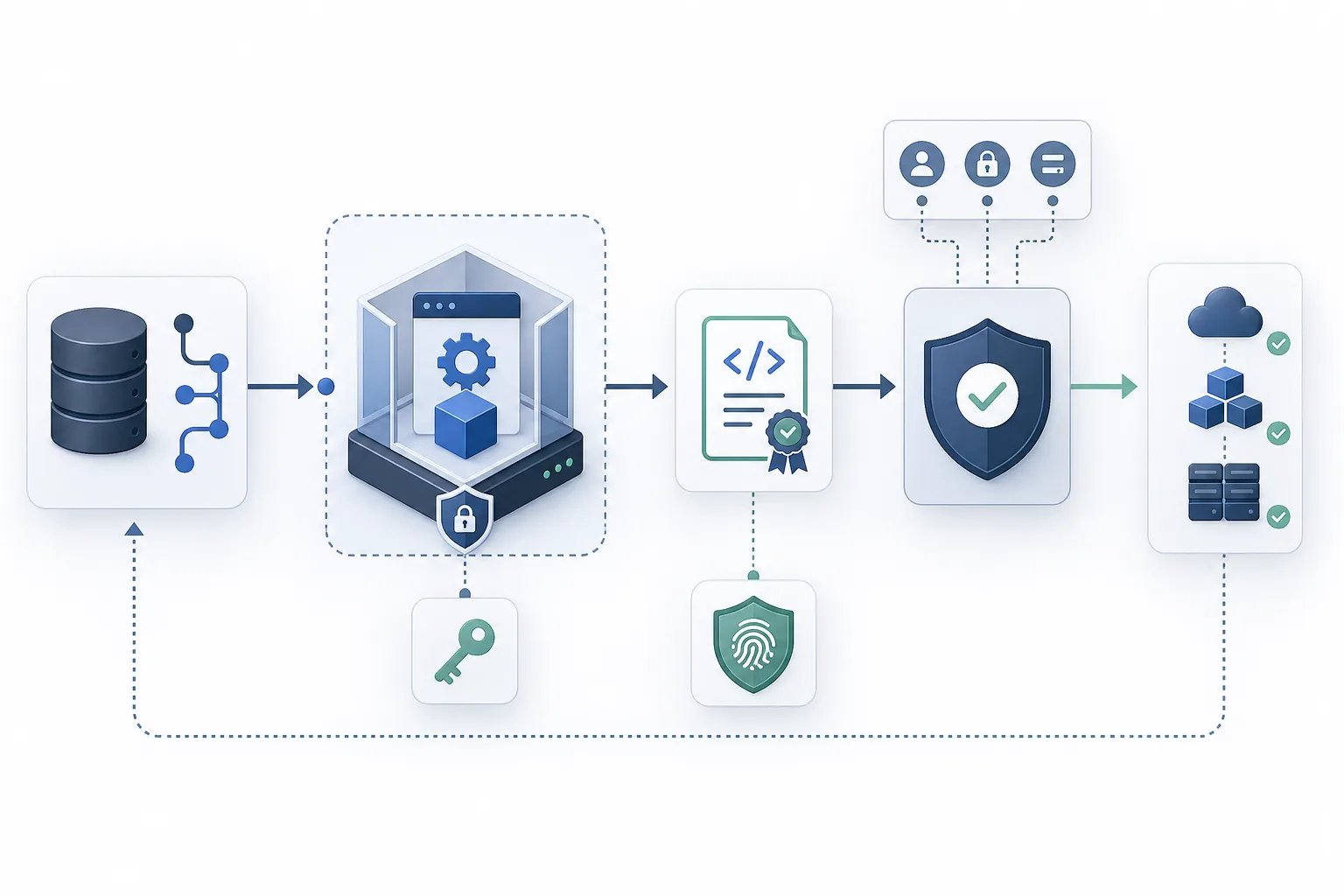
Was ist SLSA?
SLSA steht für Supply-chain Levels for Software Artifacts. Der Rahmen wurde aus Erfahrungen rund um große Software-Ökosysteme entwickelt und wird heute in der OpenSSF weitergeführt. Im Kern geht es um eine Frage: Kann ein Nutzer oder Betreiber belastbar nachvollziehen, aus welchem Quellcode ein Software-Artefakt entstanden ist, welcher Build-Prozess verwendet wurde und ob unterwegs manipuliert werden konnte?
SLSA definiert dafür Anforderungen an Build-Plattformen, Provenance-Nachweise, Isolation, Integrität und Verantwortlichkeiten. Provenance bedeutet Herkunftsnachweis: Ein maschinenlesbares Dokument beschreibt, welcher Code, welche Abhängigkeiten, welche Build-Anweisungen und welche Umgebung ein bestimmtes Artefakt erzeugt haben. Damit wird aus einem bloßen Download ein überprüfbarer Liefergegenstand.

Wie funktioniert SLSA praktisch?
Praktisch beginnt SLSA mit einer nüchternen Bestandsaufnahme. Welche Artefakte werden veröffentlicht? Wo laufen Builds? Wer darf Build-Konfigurationen ändern? Welche Abhängigkeiten werden zur Build-Zeit nachgeladen? Werden Artefakte signiert? Gibt es getrennte Rollen für Code-Änderungen, Review, Build und Release? Erst wenn diese Kette sichtbar ist, lässt sie sich absichern.
Ein typischer SLSA-orientierter Prozess erzeugt Build-Artefakte nicht auf dem Laptop eines Entwicklers, sondern in einer kontrollierten Build-Umgebung. Diese Umgebung erstellt automatisch einen Provenance-Nachweis, der kryptografisch an das Artefakt gebunden werden kann. Später kann ein Deployment-System oder ein Sicherheitsteam prüfen, ob das Artefakt aus dem erwarteten Repository, mit der erwarteten Build-Definition und auf einer vertrauenswürdigen Plattform entstanden ist.
Die SLSA-Level: Reifegrad statt Produktversprechen
SLSA arbeitet mit Reifegraden. Die genaue Ausgestaltung hat sich zwischen Versionen weiterentwickelt, die Idee bleibt aber gleich: Organisationen sollen nicht behaupten müssen, sofort perfekt zu sein. Stattdessen erhöhen sie schrittweise die Belastbarkeit ihrer Software-Lieferkette. Niedrigere Stufen schaffen Transparenz und Nachweise, höhere Stufen verlangen stärkere Schutzmaßnahmen gegen Manipulation.
Der wichtigste Lerneffekt: Ein höherer SLSA-Level ist kein Marketinglabel für sichere Software im absoluten Sinn. Er sagt aus, dass bestimmte Teile des Entstehungsprozesses definierte Anforderungen erfüllen. Das reduziert Risiko, ersetzt aber weder Schwachstellenmanagement noch sichere Architektur, Code-Reviews, Laufzeit-Härtung oder Incident Response.
Provenance, Signaturen und SBOM: Was gehört zusammen?
SLSA wird oft mit SBOMs, Signaturen und Attestations in einen Topf geworfen. Diese Dinge ergänzen sich, beantworten aber unterschiedliche Fragen. Eine SBOM beschreibt, welche Komponenten in Software stecken. Eine Signatur kann bestätigen, dass ein Artefakt von einem bestimmten Schlüssel freigegeben wurde. Eine SLSA-Provenance erklärt, wie und wo dieses Artefakt gebaut wurde.
In einer reifen Lieferkette werden diese Nachweise kombiniert. Die SBOM hilft bei der Bewertung von Abhängigkeiten, Provenance hilft bei der Bewertung des Build-Wegs, Signaturen und Policy-Engines helfen bei der Durchsetzung im Deployment. So kann eine Organisation zum Beispiel blockieren, dass Container ohne vertrauenswürdige Herkunft oder ohne passende Signatur in Produktion gelangen.
Welche Angriffe erschwert SLSA?
SLSA adressiert besonders Manipulationen zwischen Quellcode und ausgeliefertem Artefakt. Dazu gehören heimlich geänderte Build-Skripte, manipulierte CI-Runner, nachträglich ersetzte Binärdateien, unkontrollierte Release-Prozesse oder Artefakte, die nicht aus dem offiziellen Quellcode entstanden sind. Genau diese Grauzone war lange schwer zu prüfen.
Nicht jeder Angriff verschwindet dadurch. Wenn ein berechtigter Entwickler absichtlich schädlichen Code einbringt und der Review-Prozess versagt, braucht es zusätzliche Kontrollen. Auch verwundbare Abhängigkeiten werden durch SLSA nicht automatisch sicher. Der Wert liegt darin, dass der Lieferprozess weniger blind vertraut werden muss und Manipulationen wahrscheinlicher auffallen.
Was bedeutet das für Unternehmen?
Für Unternehmen ist SLSA besonders interessant, wenn Software geschäftskritisch ist, regulatorische Nachweise verlangt werden oder viele interne und externe Komponenten zusammenfließen. Banken, Industrie, Energie, Gesundheitswesen, Behörden und Plattformbetreiber brauchen nicht nur schnelle Releases, sondern nachvollziehbare Releases. SLSA liefert dafür ein gemeinsames Vokabular.
Der Einstieg muss nicht riesig sein. Teams können zunächst CI/CD-Pipelines dokumentieren, manuelle Release-Schritte reduzieren, Berechtigungen auf Build-Systemen einschränken, Artefakte signieren und Provenance-Daten erzeugen. Danach wird entschieden, welche Produkte höhere Anforderungen brauchen. Kritische Plattformkomponenten verdienen andere Kontrollen als ein internes Testwerkzeug.
Welche Kennzahlen und Kontrollen sind wichtig?
Für die Steuerung reicht es nicht, einen SLSA-Level als Ziel an eine Roadmap zu schreiben. Sinnvoller sind messbare Kontrollen: Wie hoch ist der Anteil der produktiven Artefakte mit Provenance? Welche Builds laufen in isolierten, gehärteten Umgebungen? Wie viele Releases enthalten manuelle Zwischenschritte? Welche Paketquellen sind erlaubt, und welche Deployments werden durch Policy-Regeln blockiert?
Auch Zeitpunkte sind wichtig. Ein Nachweis, der erst nachträglich manuell erzeugt wird, hat weniger Aussagekraft als ein automatisch beim Build entstandener, unveränderbar gespeicherter Nachweis. Ebenso muss klar sein, wo die Vertrauenskette endet. Wenn Signing-Keys schlecht geschützt sind oder jeder die Pipeline-Konfiguration ändern darf, hilft die schönste Attestation nur begrenzt.
Wie führt man SLSA sinnvoll ein?
Ein pragmatischer Einstieg beginnt bei den kritischsten Artefakten: Container-Images, interne Basispakete, gemeinsam genutzte Libraries, Infrastruktur-Code oder Software, die an Kunden ausgeliefert wird. Für diese Artefakte wird zuerst festgelegt, welcher Quellcode autoritativ ist, welche Build-Definition gilt und welche Plattform den Build erzeugen darf. Danach folgen Signatur, Provenance und Durchsetzung in Test- oder Produktionsumgebungen.
Wichtig ist die Reihenfolge. Wer sofort mit einer sehr hohen Zielstufe startet, erzeugt oft Frust und Umgehungslösungen. Besser ist ein Pfad, der Transparenz, Automatisierung und Policy-Durchsetzung schrittweise verbindet. So entsteht nicht nur ein Compliance-Nachweis, sondern ein Sicherheitsmechanismus, der Entwicklern im Alltag möglichst wenig im Weg steht und trotzdem riskante Artefakte stoppt.
Grenzen und typische Missverständnisse
Ein häufiges Missverständnis lautet: Wenn ein Artefakt SLSA-konform gebaut wurde, sei es automatisch frei von Schwachstellen. Das stimmt nicht. SLSA bewertet vor allem die Integrität des Entstehungsprozesses. Ob der Code fachlich korrekt, sicher programmiert oder frei von bekannten CVEs ist, muss weiterhin durch andere Verfahren geprüft werden.
Ein zweites Missverständnis betrifft die Tool-Frage. SLSA ist kein einzelnes Produkt, das man kauft und einschaltet. Viele Werkzeuge können helfen, etwa Build-Plattformen, Signing-Tools, Policy-Controller oder Attestation-Frameworks. Entscheidend bleibt aber die Prozessarchitektur: Wer darf was ändern, welche Nachweise entstehen automatisch, und welche Systeme akzeptieren nur geprüfte Artefakte?
Fazit
SLSA macht Software-Lieferketten überprüfbarer. Der Rahmen hilft Teams, den Weg vom Quellcode zum Artefakt nicht als Blackbox zu behandeln, sondern als kontrollierte, dokumentierte und technisch abgesicherte Kette. Besonders stark ist SLSA dort, wo automatisierte Builds, Provenance, Signaturen und Deployment-Policies zusammenspielen.
Der wichtigste Punkt ist die Haltung dahinter: Vertrauen entsteht nicht mehr nur durch den Namen eines Anbieters oder Repositories, sondern durch prüfbare Nachweise. Für moderne Softwareentwicklung ist das ein notwendiger Schritt, weil die Lieferkette selbst längst Teil der Angriffsfläche geworden ist.
Quellen und weiterführende Informationen
Der Artikel basiert auf öffentlich zugänglichen Fach- und Institutionsquellen. Wichtige Ausgangspunkte für die Recherche waren:
- SLSA Specification v1.1
- OpenSSF SLSA project
- SLSA Provenance specification
- NIST Software Supply Chain Security Guidance
Hinweis: Für diesen Artikel wurden KI-gestützte Recherche- und Editierwerkzeuge verwendet. Der Inhalt wurde menschlich redaktionell geprüft. Stand: 27.04.2026.