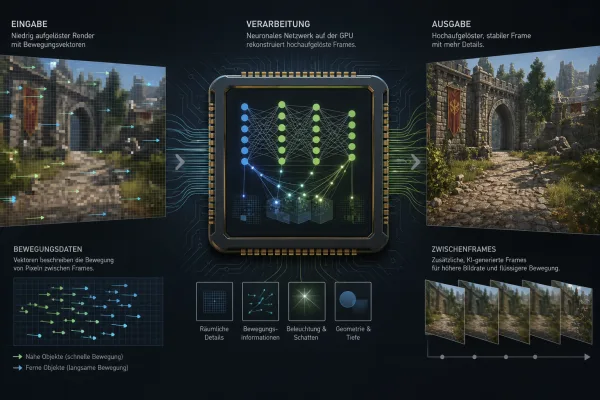
TensorFlow 2.21 bringt ein wichtiges Update für On‑Device‑KI ohne Cloud. Mit dem neuen Runtime‑System LiteRT lassen sich KI‑Modelle direkt auf GPU oder NPU eines Geräts ausführen. Das Ziel: schnellere Reaktionen, weniger Datenübertragung und mehr Funktionen, die auch offline funktionieren. Für Entwickler bedeutet das neue Wege, Modelle aus Frameworks wie PyTorch auf Smartphones oder Edge‑Geräten zu bringen. Für Nutzer zeigt sich der Effekt in Apps, die Bilder, Sprache oder Text lokal auswerten können. Der 60‑Sekunden‑Check zeigt, warum TensorFlow 2.21 und LiteRT im Alltag relevant werden.
Einleitung
Viele Apps nutzen KI, doch ein großer Teil der Berechnungen passiert noch immer in der Cloud. Das bedeutet Datenübertragung, Wartezeit und laufende Serverkosten. Genau hier setzt TensorFlow 2.21 an. Mit der neuen Laufzeitumgebung LiteRT sollen KI‑Modelle stärker direkt auf dem Gerät laufen.
Für dich als Nutzer ist das mehr als ein technisches Detail. Wenn eine App Text erkennt, Fotos analysiert oder Sprache versteht, entscheidet der Ort der Berechnung über Tempo, Datenschutz und Energieverbrauch. Läuft das Modell lokal, kann die Funktion auch ohne Internet reagieren. Gleichzeitig bleiben sensible Daten auf dem Gerät.
Google beschreibt LiteRT als nächste Entwicklungsstufe der bisherigen TensorFlow‑Lite‑Technologie. Das System nutzt vorhandene Hardware besser aus, etwa Grafikprozessoren oder spezialisierte KI‑Chips in Smartphones. Das Ziel ist klar: mehr KI‑Funktionen direkt auf dem Gerät.
Was sich technisch verändert hat und warum das für Apps und Geräte spürbar werden kann, zeigt der schnelle Überblick zu TensorFlow 2.21.
Was sich mit TensorFlow 2.21 konkret ändert
Das wichtigste neue Element in TensorFlow 2.21 heißt LiteRT. Dabei handelt es sich um eine spezialisierte Laufzeitumgebung für KI‑Modelle auf Geräten wie Smartphones, Kameras oder kleinen Industriecomputern.
Laut Google ersetzt LiteRT langfristig den bisherigen Ansatz TensorFlow Lite. Die neue Runtime ist stärker auf moderne Hardware zugeschnitten. Dazu gehören GPU‑Beschleunigung und der Einsatz von NPUs. Eine NPU ist ein spezieller Prozessor für KI‑Berechnungen, der viele Rechenschritte parallel ausführen kann.
Google beschreibt LiteRT als neue Generation der On‑Device‑Runtime, die Modelle effizient auf CPU, GPU oder NPU ausführen kann.
In ersten Angaben nennt Google eine etwa 1,4‑fache GPU‑Geschwindigkeit im Vergleich zur bisherigen TFLite‑Ausführung. Wie stark dieser Vorteil ausfällt, hängt allerdings vom jeweiligen Gerät und den Treibern ab. Entwickler müssen reale Tests auf ihrer Zielhardware durchführen.
| Merkmal | Beschreibung | Wert |
|---|---|---|
| GPU‑Beschleunigung | Optimierte Ausführung für Grafikprozessoren auf Edge‑Geräten | ca. 1,4× schneller laut Google |
| NPU‑Support | Nutzung spezialisierter KI‑Chips in Smartphones oder Embedded‑Geräten | abhängig vom Geräte‑Treiber |
| PyTorch‑Konvertierung | Neue Tools wandeln PyTorch‑Modelle in LiteRT‑Modelle um | Beta‑Status |
Warum On‑Device‑KI ohne Cloud immer wichtiger wird
Die Idee hinter On‑Device‑KI ohne Cloud ist einfach. Anstatt Daten an Server zu senden, verarbeitet das Gerät sie selbst. Das reduziert Netzwerkverkehr und kann Funktionen deutlich schneller reagieren lassen.
Ein weiterer Vorteil liegt beim Datenschutz. Fotos, Audio oder Texte müssen nicht automatisch an externe Server übertragen werden. Für viele Anwendungen, etwa in Medizin, Industrie oder Verwaltung, ist das ein entscheidender Punkt.
Auch wirtschaftlich spielt das eine Rolle. Cloud‑KI verursacht laufende Infrastrukturkosten. Wenn Modelle lokal laufen, verschiebt sich der Aufwand stärker auf das Gerät selbst.
Genau deshalb investieren viele Plattformen in lokale KI‑Technik. Apple nutzt Core ML, Microsoft und andere Projekte arbeiten mit ONNX Runtime, während Google mit TensorFlow und LiteRT eine eigene Lösung für Edge‑Geräte verfolgt.
Für Entwickler entsteht dadurch ein neuer Wettbewerb um effiziente Runtime‑Systeme. Wer Modelle schneller und energieeffizient auf Smartphones oder IoT‑Geräten ausführt, kann neue Funktionen anbieten.
Ein Beispiel aus dem Alltag: KI direkt auf dem Smartphone
Der Nutzen von On‑Device‑KI zeigt sich gut bei Kamera‑ und Scan‑Apps. Wenn eine App Text erkennt, Objekte markiert oder Dokumente automatisch ausrichtet, arbeitet im Hintergrund ein neuronales Netzwerk.
Früher wurden solche Bilder oft an Cloud‑Server geschickt. Heute können viele Geräte diese Analyse lokal erledigen. Das Foto bleibt auf dem Smartphone, während das Modell direkt darauf arbeitet.
LiteRT soll genau solche Anwendungen beschleunigen. Wenn ein Modell GPU oder NPU nutzen kann, sinkt die Wartezeit zwischen Aufnahme und Ergebnis.
Trotzdem gibt es Grenzen. Lokale KI hängt stark von der Hardware ab. Ein aktuelles Smartphone mit KI‑Chip kann komplexe Modelle ausführen. Ein älteres Gerät muss möglicherweise auf CPU‑Berechnung zurückgreifen.
Außerdem müssen Entwickler ihre Modelle anpassen. Wenn ein Operator oder Datentyp nicht unterstützt wird, kann ein Teil der Berechnung wieder auf die CPU fallen. Dann verschwindet der Geschwindigkeitsvorteil schnell.
Was Entwickler und Nutzer jetzt prüfen sollten
Für Entwickler ist das Update vor allem ein Werkzeugwechsel. TensorFlow 2.21 erweitert die Möglichkeiten, Modelle aus verschiedenen Frameworks in eine gemeinsame Runtime zu bringen.
Besonders interessant ist der neue Konverter für PyTorch‑Modelle. Damit lassen sich trainierte Netze in das LiteRT‑Format übertragen. Der Konverter befindet sich jedoch noch im Beta‑Status, weshalb Tests auf echten Geräten wichtig bleiben.
Nutzer merken solche Änderungen indirekt. Wenn Apps stärker auf lokale KI setzen, reagieren Funktionen schneller und funktionieren häufiger offline.
Gleichzeitig entsteht eine neue Verantwortung für App‑Updates. Modelle und Runtime müssen regelmäßig aktualisiert werden, damit Sicherheitslücken geschlossen und neue Hardware unterstützt wird.
Der eigentliche Treiber dieser Entwicklung sind die Gerätehersteller. Moderne Smartphones enthalten inzwischen eigene KI‑Beschleuniger. Frameworks wie LiteRT versuchen, diese Hardware einfacher nutzbar zu machen.
Fazit
TensorFlow 2.21 zeigt, wohin sich KI‑Software entwickelt. Rechenmodelle wandern zunehmend vom Rechenzentrum direkt auf Geräte. LiteRT ist ein Schritt in diese Richtung. Die Runtime nutzt GPU und NPU stärker aus und erleichtert den Transfer von Modellen aus Frameworks wie PyTorch.
Für Nutzer bedeutet das vor allem schnellere Funktionen und mehr Offline‑KI. Für Entwickler entsteht ein neuer Werkzeugkasten, der lokale KI‑Features einfacher verfügbar macht. Gleichzeitig bleibt vieles abhängig von Hardware‑Support, Treibern und der Reife der neuen Tools.
Ob LiteRT sich als Standard für Edge‑KI etabliert, entscheidet sich in den kommenden Versionen und in der Praxis auf realen Geräten.
Wie sinnvoll findest du lokale KI direkt auf dem Gerät? Diskutiere mit und teile den Artikel mit anderen Technikinteressierten.