Schlagwort: api
-

OpenAI und Tata planen 100‑MW‑KI-Rechenzentrum in Indien
Stand: 19. February 2026, 15:46 Uhr Berlin Auf einen Blick OpenAI und die Tata Group haben eine Partnerschaft für KI-Infrastruktur in Indien vereinbart. Kernpunkt ist

OpenAI nimmt GPT-4o aus ChatGPT; API-Ende rückt näher
Stand: 14. February 2026, 17:45 Uhr Berlin Auf einen Blick OpenAI hat GPT-4o aus der ChatGPT-Oberfläche entfernt und stellt damit Nutzer und Anbieter von Integrationen

KI‑Coding‑Tools: Sicherheitsfehler mit hohen Folgekosten
KI‑Coding‑Tools beschleunigen Entwicklungsteams, doch falsch abgesicherte Accounts und Tokens können schnell teuer werden. Studien und Incident‑Reports zeigen typische Angriffsmuster: kompromittierte Zugangsschlüssel, automatisierte Cloud‑Ressourcen, massive Datenabflüsse.

Agentische Workflows: Wie KI-Agenten mit Tools zuverlässig handeln
Agentische Workflows verbinden mehrere KI-Agenten mit externen Werkzeugen, damit komplexe Aufgaben zuverlässig erledigt werden. Das Konzept “agentische Workflows” beschreibt, wie einzelne Agenten, Tool-Aufrufe und ein

On-Device KI-Agenten: Wie „Function Calling“ Apps und Geräte steuern kann
Moderne On‑Device KI-Agenten erlauben lokalen, schnellen und datensparsamen Betrieb von Assistenzfunktionen auf Smartphones und Edge‑Geräten. Ein zentrales Konzept dafür ist Function Calling: die Möglichkeit, dass

AI Gateways erklärt: Warum LLMs in Apps plötzlich Infrastruktur werden
Ein AI Gateway ist die zentrale Technik, die Anfragen an verschiedene große Sprachmodelle koordiniert und damit LLM‑Betrieb in Apps handhabbar macht. Das Stichwort AI Gateway
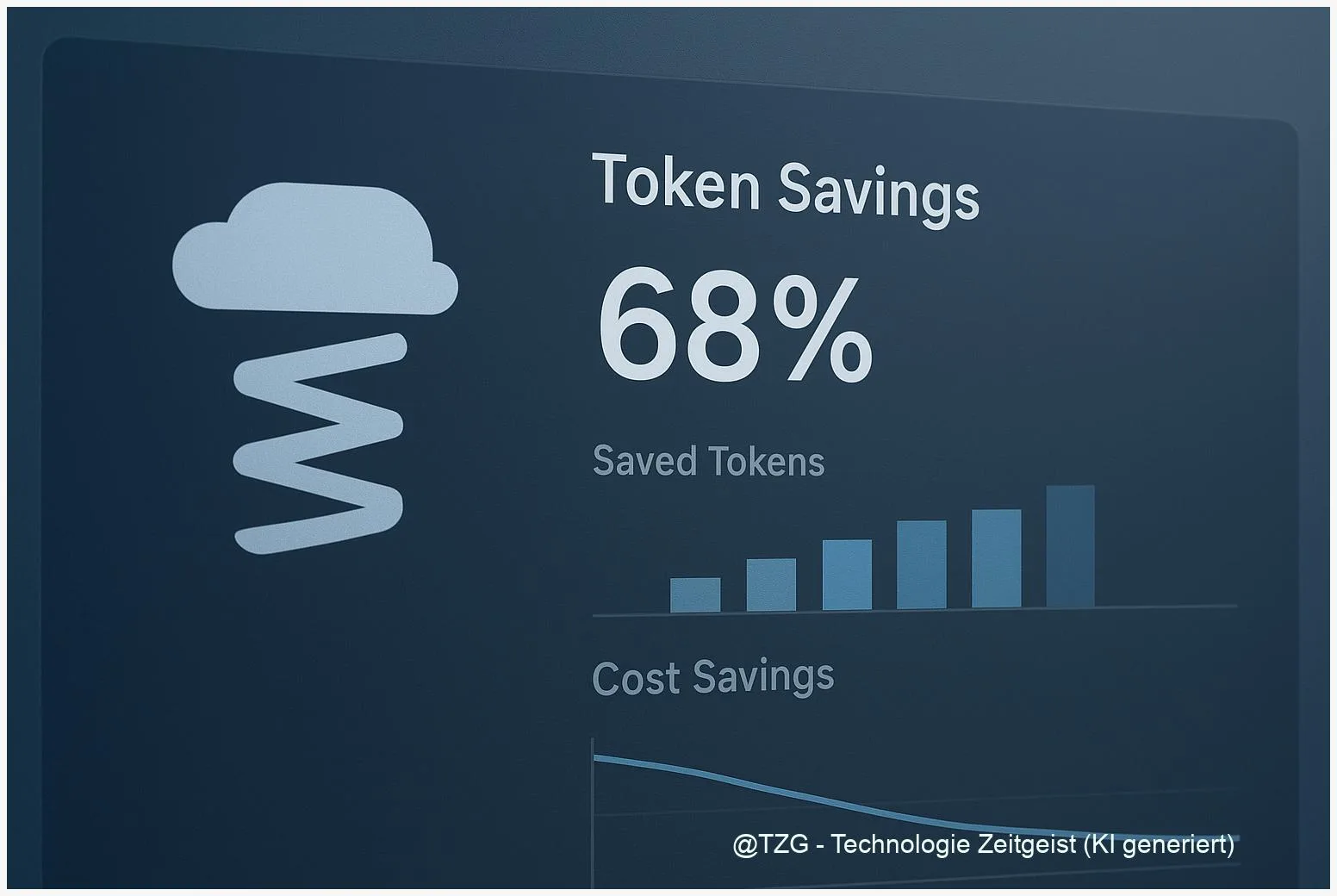
Prompt‑Compression mit LLMLingua: LLM‑API‑Kosten um 5–20× senken
Zuletzt aktualisiert: 2025-11-17 Kurzfassung Prompt compression llmlingua ist eine Technik, mit der lange Prompts verdichtet werden, um LLM‑API‑Kosten und Latenzen deutlich zu reduzieren. Dieser Praxis‑Guide
Echtzeit‑Websuche für LLMs: Tavily und LangChain praktisch nutzen
Zuletzt aktualisiert: 2025-11-16 Kurzfassung Dieser Beitrag erklärt, wie Sie Echtzeit‑Websuche für LLMs mit Tavily und LangChain in zuverlässige RAG‑Pipelines überführen. Er zeigt zentrale API‑Bausteine, Integrationstipps,
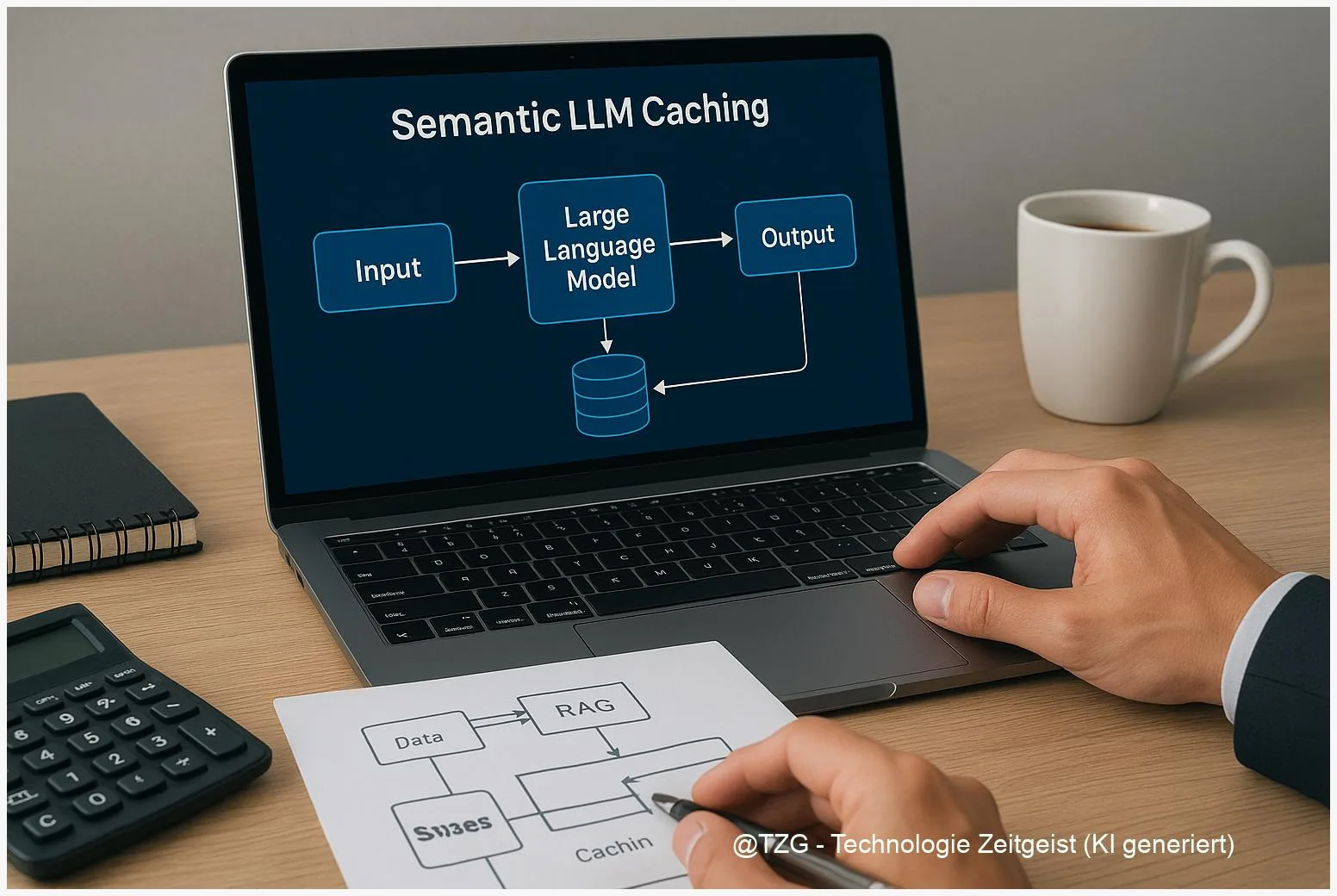
Semantic LLM Caching: RAG‑Latenz senken, API‑Kosten reduzieren
Zuletzt aktualisiert: 12. November 2025 Kurzfassung Dieser Text erklärt kompakt, wie semantic LLM caching in RAG‑Setups die Zeit bis zur Antwort verkürzen und API‑Kosten senken

Wenn Modelle über Nacht wechseln – Resiliente LLM‑Architekturen
Zuletzt aktualisiert: 10. November 2025 Kurzfassung Unternehmen sehen heute, wie Updates großer Modelle Prozesse sofort verändern können. Dieser Text zeigt praktikable Wege zur model volatility

K2 Thinking: Open‑Source Thinking Agent mit 256k Kontextfenster
Zuletzt aktualisiert: 08. November 2025 Berlin, 08. November 2025 Kurzfassung K2 Thinking ist ein Open‑Source “thinking agent” von Moonshot/Kimi mit 256k Kontextfenster. Laut Projektseite erzielt

Einführung der OpenAI Realtime API – Schnelle, Nahtlose Konversationen für Entwickler
Entdecken Sie, wie die neue Realtime API von OpenAI Entwickler dabei unterstützt, schnelle Sprach-zu-Sprach-Funktionen in Echtzeit zu integrieren, ideal für interaktive Anwendungen im Kundenservice und