KI-Code-Verifikation wird wichtiger, weil generative Coding-Tools heute mehr Quellcode in kürzerer Zeit erzeugen, klassische Review-Prozesse aber viele Produktionsfehler nur begrenzt abfangen. Der Kern des Problems: Ein Review prüft vor allem, ob Code plausibel aussieht; es beweist nicht, wie er sich unter realen Bedingungen verhält. Dieser Bericht erklärt, worin sich Review, Testing und Verifikation unterscheiden, wann zusätzliche Prüfungen wirtschaftlich sinnvoll sind und warum das Thema für Softwareteams, Sicherheitsverantwortliche und Unternehmen mit wachsendem KI-Anteil im Entwicklungsprozess praktisch relevant ist.
Das Wichtigste in Kürze
- Code-Review bleibt nützlich, erkennt aber vor allem sichtbare Logik-, Stil- und Architekturprobleme; Laufzeitfehler, Grenzfälle und Supply-Chain-Risiken entgehen ihm oft.
- Verifikation meint je nach Quelle entweder formale Korrektheitsbeweise oder, praxisnäher, eine zusätzliche Prüfschicht aus statischer Analyse, strukturierten Tests, Fuzzing und weiteren belastbaren Kontrollen.
- Je mehr KI-generierter Code in CI/CD-Pipelines landet, desto eher lohnt sich der Mehraufwand für zusätzliche Prüfungen in sicherheitskritischen, regulierten oder kostenempfindlichen Umgebungen.
Warum KI-Code-Review allein oft zu kurz greift
Die stabile Grundfrage lautet: Reicht es noch, KI-generierten Code per Review freizugeben, oder braucht es zusätzliche Verifikation? Für viele Teams ist das keine akademische Debatte mehr. Wenn Assistenten in IDEs, Pull-Requests und Build-Prozessen mehr Code erzeugen, steigt nicht nur das Tempo, sondern auch die Menge an Stellen, an denen Fehler unauffällig durchrutschen können. Ein sauber formulierter Patch kann trotzdem unsichere Abhängigkeiten einführen, Randfälle übersehen oder unter Last anders reagieren als erwartet.
Genau deshalb verschiebt sich der Markt von reiner Code-Erzeugung hin zu belastbarer Qualitätskontrolle. Dass Investoren auf diesen Bereich setzen, zeigt die Debatte um Anbieter wie Qodo. Über eine 70-Millionen-Dollar-Finanzierung wurde Ende März 2026 berichtet; eine offizielle Primärbestätigung dieser Summe lag im Recherchefenster allerdings nicht vor. Für die Einordnung ist die exakte Zahl auch nicht der Hauptpunkt. Wichtiger ist, warum Verifikation, Simulation und zusätzliche Teststufen als zweite Schicht neben dem Review an Bedeutung gewinnen.
Review findet vieles, aber nicht das Verhalten unter realen Bedingungen
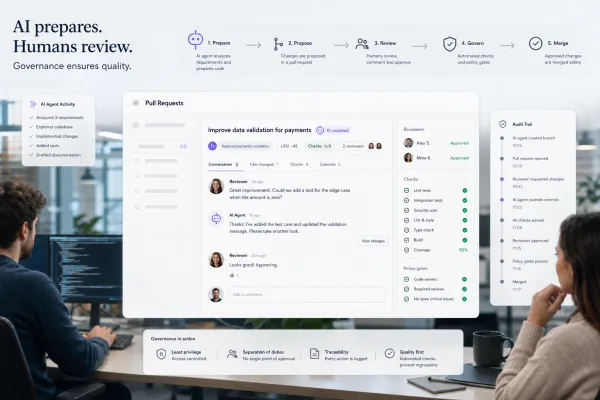
Ein Code-Review ist im Kern eine Sichtprüfung. Menschen oder unterstützende Tools kontrollieren, ob ein Änderungssatz verständlich, konsistent und grob plausibel ist. Das hilft bei Stilfragen, lesbarer Architektur, offensichtlichen Logikfehlern und bei Stellen, an denen Teamregeln verletzt werden. Gerade bei KI-generiertem Code ist das wichtig, weil Modelle oft lokal überzeugende Lösungen liefern, die sich gut lesen, aber nicht sauber in das Gesamtsystem passen.
Die Grenze beginnt dort, wo die Qualität nicht mehr am Text allein hängt. Ob ein Modul nur unter bestimmten Eingaben abstürzt, eine Speichergrenze reißt, mit alten Testfällen kollidiert oder in einer Build-Umgebung ein halluziniertes Paket nachlädt, zeigt ein Review oft nicht zuverlässig. Der Fachbericht des Center for Security and Emerging Technology beschreibt genau solche Risiken bei KI-generiertem Code: von nicht existierenden Paketen bis zu schweren Speicherfehlern. In einer eigenen Auswertung ließen sich viele Beispiele nicht erfolgreich verifizieren. Das spricht nicht gegen Review, sondern gegen die Annahme, Review könne die gesamte Absicherung ersetzen.
Was mit Verifikation gemeint ist und warum der Begriff unscharf sein kann
Bei Verifikation lohnt ein genauer Blick, weil der Begriff je nach Quelle enger oder breiter verwendet wird. In der klassischen Informatik steht er oft für den formalen Nachweis, dass ein Programm eine definierte Eigenschaft tatsächlich erfüllt. Das ist präzise, aber im Alltag vieler Entwicklungsteams nur für ausgewählte Komponenten praktikabel. Das NIST verwendet den Begriff in seinen Leitlinien für Entwickler-Verifikation breiter und operativer: Dazu zählen dort unter anderem automatisierte Tests, statische Codeanalyse, Black-Box-Tests, strukturbasierte Testfälle und Fuzzing.
Für die Praxis ist diese breitere Lesart meist hilfreicher. Gemeint ist dann nicht ein mathematischer Beweis für jedes Stück Code, sondern eine belastbare Prüfschicht, die mehr leistet als menschliches Gegenlesen. Testing beantwortet, wie sich Software in ausgewählten Szenarien verhält. Verifikation im breiten Sinn erhöht die Sicherheit, dass wichtige Eigenschaften systematisch geprüft wurden. Simulationsnahe Testumgebungen, Property-Checks, Fuzzing oder Security-Scans gehören deshalb oft in dieselbe Kategorie zusätzlicher Absicherung. Wer in Teams über KI-Code-Verifikation spricht, sollte den Begriff trotzdem sauber definieren, damit niemand Review, Testing und formale Verifikation durcheinanderwirft.
Wann zusätzliche Prüfungen wirtschaftlich sinnvoll werden
Mehr Kontrolle kostet Zeit, Rechenleistung und Prozessdisziplin. Sie lohnt sich also nicht automatisch für jede kleine Änderung. Wirtschaftlich sinnvoll wird der Mehraufwand dort, wo ein Fehler deutlich teurer ist als eine zusätzliche Prüfstufe: in sicherheitskritischen Systemen, bei produktionsnaher Infrastruktur, im Zahlungsverkehr, in Medizin-, Industrie- oder Automotive-Software und überall dort, wo Ausfälle, Rückrufe oder Sicherheitsvorfälle hohe Folgekosten verursachen. Auch bei internen Geschäftsanwendungen kann sich das rechnen, wenn viele KI-generierte Änderungen in kurzer Folge deployt werden und die Zahl der möglichen Seiteneffekte steigt.
Umgekehrt bleibt klassisches Review in risikoärmeren Bereichen oft ausreichend, etwa bei klar begrenzten UI-Anpassungen oder gut getesteten Routineänderungen mit kleiner Reichweite. Entscheidend ist weniger die Herkunft des Codes als seine Wirkung. KI-Code-Verifikation ist vor allem dann sinnvoll, wenn drei Faktoren zusammenkommen: hohe Änderungsfrequenz, schwer überschaubare Abhängigkeiten und ein hohes Schadenspotenzial im Fehlerfall. Dann sinkt der Grenznutzen des reinen Reviews, während zusätzliche Tests, statische Analysen und reproduzierbare Prüfketten ihren Aufwand schneller rechtfertigen.
Für Unternehmen zählt nicht nur Sicherheit, sondern auch Nachweisbarkeit
Für CTOs, DevOps-, QA- und Sicherheitsverantwortliche geht es nicht nur darum, Bugs zu vermeiden. Ebenso wichtig ist die Frage, wie sich Qualität im Prozess nachweisen lässt. Solange einzelne Entwickler KI-Vorschläge nur überfliegen und dann mergen, bleibt viel implizit. In größeren Organisationen reicht das selten. Dort müssen Teams zeigen können, welche Checks vor dem Merge liefen, welche Testabdeckung relevant war, welche statischen Befunde offen geblieben sind und welche Abhängigkeiten bewusst freigegeben wurden.
Gerade für deutsche und europäische Unternehmen ist das praktisch relevant, weil viele Softwareprodukte heute Teil größerer Lieferketten sind. Fehler landen nicht isoliert in einem Entwickler-Branch, sondern in Kundenumgebungen, SaaS-Plattformen, Industrieanlagen oder internen Kernsystemen. KI beschleunigt die Erstellung von Code, aber nicht automatisch die Belastbarkeit der Freigabe. Wer die Qualitätskontrolle nicht mit skaliert, verschiebt das Problem nur nach hinten: in Störungen, Incident-Response, Hotfixes und Vertrauensverlust. Der operative Wert von Verifikation liegt deshalb oft weniger im perfekten Code als in verlässlicheren Freigabeentscheidungen.
Warum der Markt von Generierung zu Qualitätskontrolle weiterzieht
Die erste Welle von KI-Coding-Tools wurde vor allem darüber verkauft, wie schnell sie Funktionen, Tests oder Dokumentation erzeugen. Mit wachsender Nutzung rückt eine zweite Frage nach vorn: Wie wird dieser Output überprüfbar genug für Produktion? Genau an diesem Punkt wird Verifikation zum eigenen Produktfeld. Nicht, weil Review verschwindet, sondern weil seine Rolle klarer wird. Review ist eine menschliche Plausibilitätskontrolle. Produktionsreife entsteht erst durch zusätzliche Belege: reproduzierbare Tests, Analyseergebnisse, Security-Prüfungen und sauber dokumentierte Freigabekriterien.
Darum ist auch die Qodo-Debatte mehr als eine Finanzierungsnotiz. Ob die berichteten 70 Millionen Dollar im Detail bereits primär bestätigt sind oder nicht, ändert wenig an der Marktrichtung. Anbieter versuchen, Verifikation näher an IDEs, Pull-Requests und CI/CD-Stacks zu bringen, damit Qualitätssicherung nicht erst kurz vor dem Release beginnt. Der wahrscheinliche Standard für viele Teams ist deshalb nicht Vollautomatisierung, sondern eine mehrschichtige Pipeline: KI erzeugt, Menschen reviewen, Systeme verifizieren.
Verifikation wird zur zweiten Schicht neben dem Review
KI-generierter Code macht Softwareentwicklung schneller, aber Geschwindigkeit ersetzt keine Absicherung. Ein Review bleibt wertvoll, weil es Kontext, Architektur und offensichtliche Schwächen sichtbar macht. Es reicht nur dann nicht mehr aus, wenn Risiken erst im Verhalten, in Abhängigkeiten oder unter realen Lastbedingungen sichtbar werden. Genau dort setzt KI-Code-Verifikation an: als zusätzliche, nachvollziehbare Prüfschicht zwischen plausibel wirkendem Code und verantwortbarer Produktion. Für Teams heißt das nicht, jeden Commit formal zu beweisen. Es heißt, die Tiefe der Prüfung an Schadenspotenzial, Systemkritik und Änderungsdynamik auszurichten. Wer KI produktiv nutzen will, braucht deshalb nicht weniger Review, sondern besser abgestufte Kontrolle.
Die praktikabelste Frage lautet nicht, ob Verifikation nötig ist, sondern an welcher Stelle sie im eigenen Prozess den größten Sicherheitsgewinn liefert.