Schlagwort: Datenbank
-
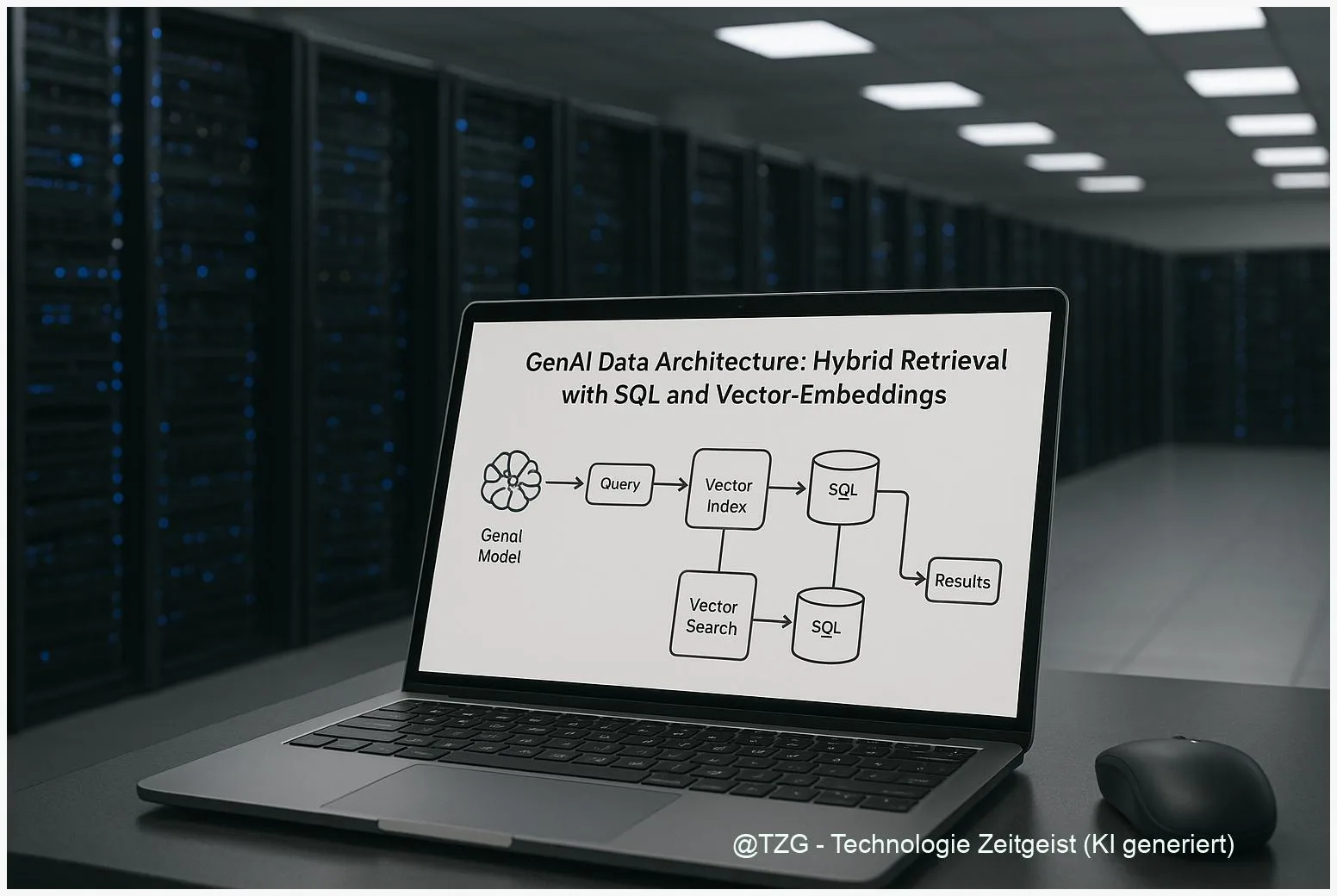
GenAI Datenarchitektur: Hybrid Retrieval mit SQL und Vector-Embeddings
Die GenAI Datenarchitektur entscheidet, wie Unternehmen Wissen verlässlich für generative Modelle abrufen. Hybrid Retrieval verbindet dichte Vector‑Embeddings mit klassischer SQL‑ oder Keyword‑Suche und reduziert so

Wie man Daten‑Drift erkennt: Datenqualität für KI im Betrieb
Datenqualität für KI entscheidet im Betrieb oft darüber, ob Vorhersagen verlässlich bleiben. Dieses Kurzportrait erklärt, warum Daten‑ und Konzept‑Drift auftreten, wie gängige Erkennungsverfahren funktionieren und

RAG-Dokumentkompression: Effizient große Textsammlungen nutzen
RAG Dokumentkompression hilft, riesige Textbestände so zu verkleinern, dass semantische Suche und generative Modelle weiterhin korrekte Antworten liefern. In diesem Text steht, wie Produktquantisierung, semantische

RAG offline betreiben: So funktioniert ein lokales Retrieval‑System sicher
RAG offline betreiben bietet die Möglichkeit, große Textsammlungen lokal zur Beantwortung von Anfragen zu nutzen, ohne Referenzdaten an externe Anbieter zu schicken. Dieser Beitrag erklärt,

RAG lokal mit Ollama und FAISS: So läuft eine Offline‑RAG
Zuletzt aktualisiert: 22. November 2025 Berlin, 22. November 2025 Insights RAG lokal mit Ollama und FAISS macht Retrieval‑Augmented Generation vollständig offline möglich. Lokale Embeddings (Ollama)

Gemini File Search vs Homebrew RAG: Kosten, Datenschutz, Debuggability
Zuletzt aktualisiert: 2025-11-22 Kurzfassung Dieser Beitrag vergleicht “Gemini File Search vs RAG” aus Sicht von Kosten, Datenschutz und Debuggability. Ich erkläre, wie Geminis Managed-Ansatz Unterschiede
Zuverlässiges RAG-Database-Management für Enterprise Search
Zuletzt aktualisiert: 2025-11-20 Kurzfassung Ein praktischer Leitfaden zu RAG database management: Wie Unternehmen Retrieval‑Augmented‑Generation verlässlich betreiben, Quellen sauber nachverfolgen und Vector‑Datenbanken stabil skalieren. Der Text
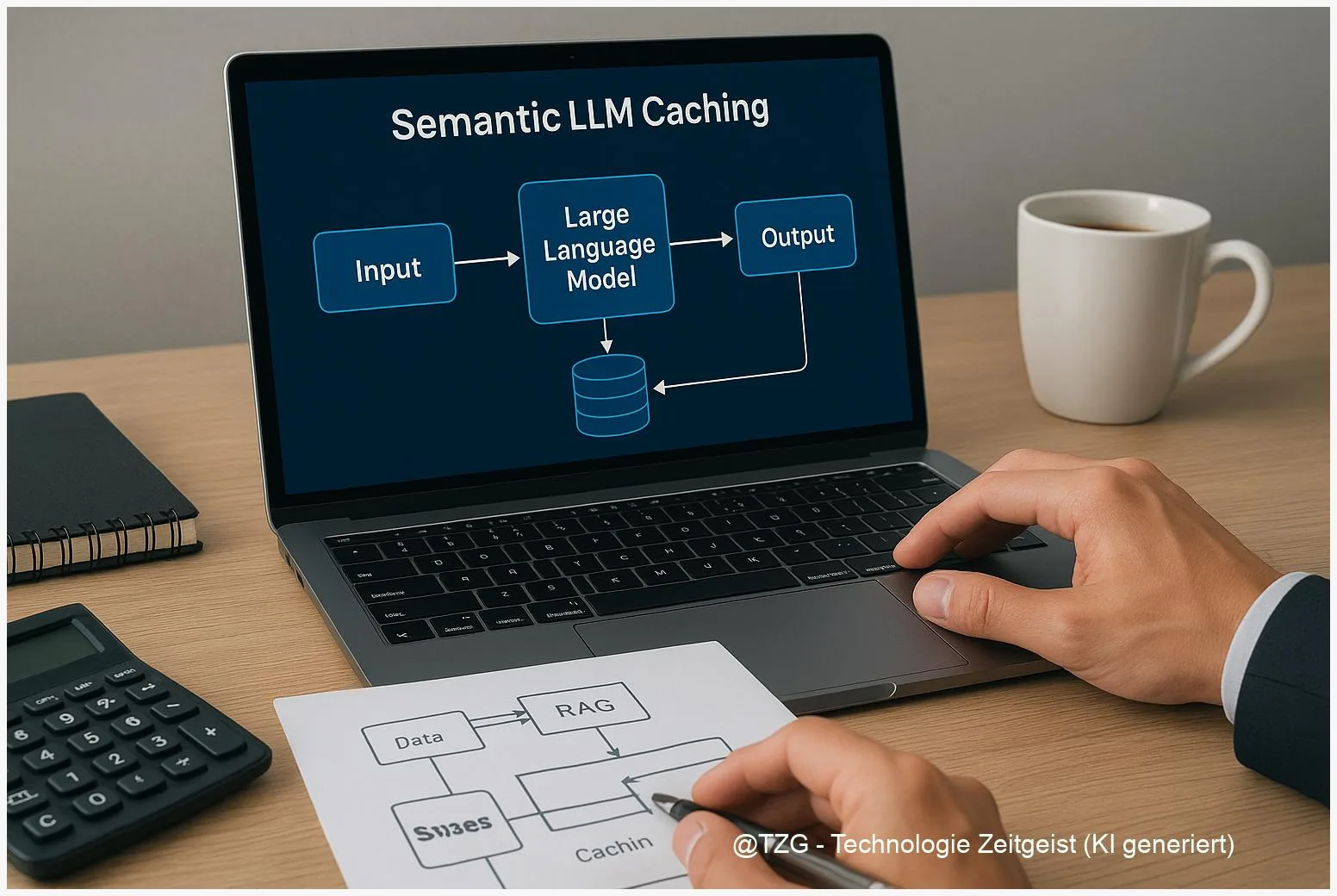
Semantic LLM Caching: RAG‑Latenz senken, API‑Kosten reduzieren
Zuletzt aktualisiert: 12. November 2025 Kurzfassung Dieser Text erklärt kompakt, wie semantic LLM caching in RAG‑Setups die Zeit bis zur Antwort verkürzen und API‑Kosten senken

Praktischer Leitfaden: Zuverlässiges Memory für LLM‑Agenten
Zuletzt aktualisiert: 10. November 2025 Kurzfassung Dieser Text erklärt praktisch, wie man zuverlässiges Memory für LLM-Agenten baut. Er vergleicht Vektor‑RAG, temporale Knowledge‑Graphs und Execution‑Logs, zeigt

Memory Datenbanken: Ein Paradigmenwechsel in der Datenverarbeitung
In der Ära der digitalen Transformation, wo Millisekunden über den Erfolg von Unternehmensanwendungen entscheiden können, erweisen sich Memory Datenbanken als eine Schlüsseltechnologie, die die Landschaft