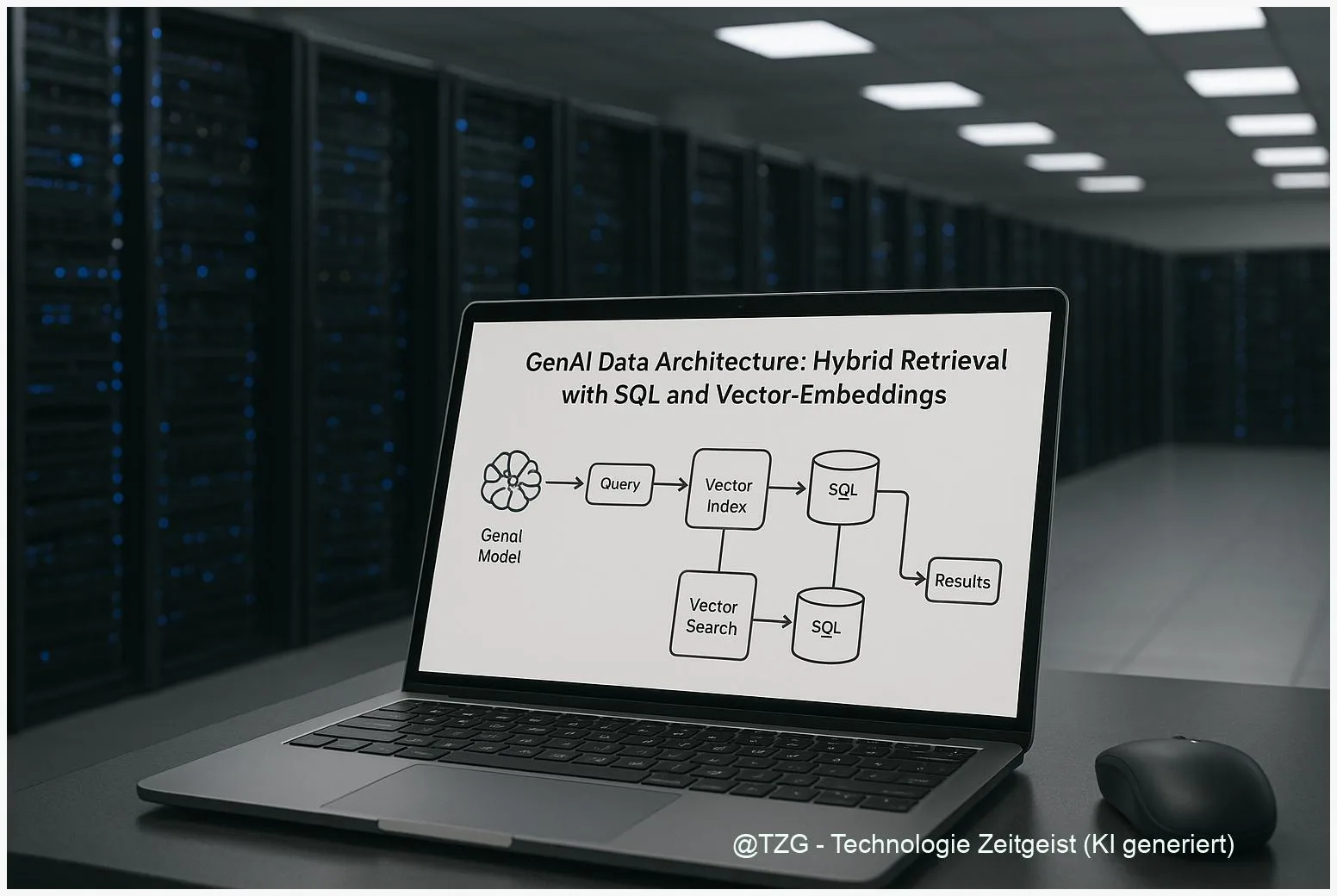
Die GenAI Datenarchitektur entscheidet, wie Unternehmen Wissen verlässlich für generative Modelle abrufen. Hybrid Retrieval verbindet dichte Vector‑Embeddings mit klassischer SQL‑ oder Keyword‑Suche und reduziert so Fehlantworten bei Retrieval‑Augmented‑Generation. Dieser Beitrag zeigt, welche Architektur‑Entscheidungen wichtig sind — von Index‑Typen über Embedding‑Pipelines bis zu Governance‑Prinzipien — und liefert praxisnahe Kriterien, um Pilotprojekte messbar zu planen.
Einleitung
Viele Organisationen haben mittlerweile große Text‑ und Datensammlungen — Handbücher, Support‑Tickets, Verträge, Produktdaten. Wenn daraus Antworten für ein generatives Modell kommen sollen, reicht ein einfacher Full‑Text‑Suchlauf oft nicht aus: Modelle können relevante Fakten übersehen oder frei erfinden. Genau hier setzt eine GenAI Datenarchitektur mit Hybrid Retrieval an. Sie kombiniert die semantische Stärke von Embeddings mit der Präzision strukturierter Abfragen, sodass Antworten fundierter, schneller und prüfbarer werden.
Der nächste Abschnitt ordnet die technischen Bausteine ein. Danach folgen konkrete Anwendungsbeispiele, typische Kompromisse zwischen Kosten und Latenz sowie Empfehlungen, wie sich ein erstes Pilotprojekt messen und weiter skalieren lässt.
GenAI Datenarchitektur: Grundlagen und Aufbau
Eine moderne GenAI Datenarchitektur besteht im Kern aus drei Schichten: (1) der Datenspeicherung und Metadaten‑Schicht (z. B. relationale DB oder Data Lake), (2) einer semantischen Schicht mit Embeddings und einem Vector‑Index, und (3) einer Retrieval‑Schicht, die Ergebnisse aus Vektor‑ und Keyword‑Abfragen zusammenführt. Diese Trennung hilft, unterschiedliche Anforderungen — Freshness, Latenz, Compliance — gezielt zu steuern.
Hybrid Retrieval vereint die Präzision von Schlüsselwort‑Filtern mit der Flexibilität semantischer Suche.
Wesentliche technische Entscheidungen betreffen den Index‑Typ: HNSW (graphbasierte ANN) liefert sehr niedrige Latenz bei ausreichend RAM, IVF‑basierte Indizes sind bei sehr großen Datenmengen kosteneffizienter, oft kombiniert mit Quantisierung (IVF+PQ), um Speicher zu sparen. Ob die Vektoren in einer spezialisierten Vector‑DB (z. B. für hohe Query‑Last) oder in einer SQL‑Engine mit Vector‑Support abgelegt werden, hängt von Betriebsaufwand und Governance‑Anforderungen ab.
Eine kompakte Vergleichstabelle hilft beim Überblick:
| Merkmal | Beschreibung | Wert |
|---|---|---|
| HNSW | Niedrige Latenz, hoher RAM‑Bedarf | gut bei niedriger Millisekunden‑Latenz |
| IVF + PQ | Speichereffizient, geringere Genauigkeit | gut bei Milliarden Vektoren |
Wichtig ist ein Metrik‑Set als Teil der Architektur: Recall@k, 95‑Perzentil‑Latenz, Cost‑per‑1k‑Queries und „groundedness“ (Anteil der Antworten, die belegbare Quellen liefern). Technische Sizing‑Formeln für HNSW erlauben erste Abschätzungen des RAM‑Bedarfs; praxisorientierte Publikationen aus 2024/2025 geben nützliche Anhaltspunkte, zugleich sollte immer ein Sample‑Index in der Zielumgebung gebaut werden.
Wie Hybrid Retrieval im Praxisfall funktioniert
In einem typischen Ablauf wird eingehender Text zuerst normalisiert: Formatierung entfernt, PII geschwärzt, Metadaten (Datum, Quelle, Dokumenttyp) annotiert. Anschließend erzeugt ein Embedding‑Modul für jede Text‑Passage einen dichten Vektor. Parallel dazu bleiben Schlüsselwörter und strukturierte Felder in einer SQL‑Schicht erhalten.
Bei einer Nutzerfrage laufen nun zwei Abfragen: eine Vektorähnlichkeits‑Suche (ANN) und eine klassische Keyword/SQL‑Abfrage. Ein Fusionsmechanismus kombiniert die Resultate, gewichtet nach Relevanz‑Scores und Metadaten‑Constraints — etwa nur Antworten aus vertrauenswürdigen Quellen oder nur aus dem letzten Jahr. Solche Filterschichten sind zentral, um Halluzinationen zu begrenzen und Compliance‑Anforderungen zu erfüllen.
Ein konkretes Beispiel: Ein Support‑Chat fragt nach einer Fehlerbehebung für ein Gerät. Die Hybrid‑Abfrage liefert ähnliche KB‑Passagen via Embeddings, ergänzt durch SQL‑gefilterte Release‑Notes für die passende Geräteversion. Das Ergebnis ist eine Antwort, die sowohl semantisch relevant als auch versionsspezifisch korrekt ist.
Technisch sollte man die Embedding‑Erzeugung nach Kosten und Freshness planen: On‑write‑Embedding (sofort beim Speichern) hält Daten aktuell, kostet aber mehr Inferenz; Batch‑Jobs sparen Kosten, verlängern jedoch die Aktualisierungsperiode. Für sensible Daten sind PII‑Redaction und Zugriffskontrollen in der Retrieval‑Schicht zwingend.
Chancen, Risiken und typische Spannungsfelder
Hybrid Retrieval bietet mehrere Vorteile: höhere Trefferqualität, bessere Nachvollziehbarkeit durch kombinierte Quellen und flexiblere Filtersysteme. Für Anwender bedeutet das oft weniger Nachfragen und höheres Vertrauen in generierte Antworten. Für Unternehmen reduziert sich das Risiko, dass Modelle völlig ungebundene Antworten liefern.
Auf der anderen Seite gibt es deutliche Spannungen: Speicher und Kosten versus Genauigkeit; Echtzeit‑Freshness versus Inferenzkosten; sowie Datenschutz‑ und Governance‑Anforderungen. So kann ein HNSW‑Index bei hoher Dimensionalität viel RAM benötigen; Quantisierung reduziert Speicher, aber kann Recall kosten. Deshalb sind Messungen mit realen Daten und klaren Akzeptanzkriterien essenziell.
Ein weiteres Risiko ist Embedding‑Drift: Wenn sich Sprache oder Dokumenttypen ändern, verschlechtert sich die semantische Suche. Regelmäßiges Monitoring (z. B. Recall‑Tests gegen annotierte Queries) und geplante Reindex‑Intervalle verringern das Problem. Ebenfalls wichtig sind Logging und Audit‑Spuren: Welche Quelle hat ein Ergebnis geliefert, wann wurde es zuletzt aktualisiert und wer durfte darauf zugreifen?
Schließlich bestehen Unsicherheiten bei Benchmarks: Vergleichsstudien zwischen Anbietern sind oft nicht 1:1 übertragbar. Unternehmen sollten daher eigene Benchmarks mit representative Workloads durchführen, bevor sie sich auf einen Anbieter festlegen.
Nächste Schritte und Skalierungsszenarien
Ein praktikabler Fahrplan beginnt mit einem klar abgegrenzten Pilot: eine Domäne mit moderate Datenmenge, definierte Metriken (Recall@10, 95p latency, groundedness) und Zeitraum (z. B. 3 Monate). Das erlaubt, Annahmen über Kosten, Update‑Rhythmen und Governance zu prüfen, bevor größere Investitionen folgen.
Bei positivem Pilot ergibt sich eine natürliche Skalierungsfrage: Soll eine integrierte SQL‑Engine mit Vector‑Support oder eine spezialisierte Vector‑DB genutzt werden? Regelbasiert lautet eine gängige Empfehlung: wenn relationale Daten dominieren und Governance zentral sein muss, ist eine integrierte Lösung vorteilhaft; bei sehr hohen ANN‑Skalen oder komplexen Re‑Ranking‑Pipelines kann eine Speziallösung sinnvoller sein.
Architekturentscheidungen sollten immer an messbaren Kriterien ausgerichtet werden: Latenzziele, Query‑Per‑Second‑Ziel, Aktualitätsanforderungen und Compliance‑Grenzen. Operationalisierung heißt zudem: automatisierte Reindex‑Jobs, Monitoring‑Dashboards für Embedding‑Drift und eine klare Dokumentation von PII‑Regeln. So bleibt die GenAI Datenarchitektur langfristig belastbar.
Fazit
Eine zukunftsfähige GenAI Datenarchitektur baut auf dem Zusammenspiel von Vector‑Embeddings und strukturierten Daten auf. Hybrid Retrieval liefert in vielen Unternehmensfällen die beste Balance aus Relevanz, Nachvollziehbarkeit und Kostenkontrolle. Entscheidend sind klare Messgrößen, frühe Pilotversuche und eine konsequente Governance, die PII‑Handling, Auditierbarkeit und Aktualität sicherstellt. Wer diese Elemente kombiniert, schafft eine Basis, auf der generative Modelle sinnvoll und verantwortbar antworten können.





Schreibe einen Kommentar